CompTIA Security+

Dominio 1.0 Conceptos generales de seguridad
1.1 Comparar y contrastar diversos tipos de controles de seguridad
Categorías;
- Controles Tecnicos; son controles implementados mediante sistemas, controles de sistema operativos, firewalls, anti-virus.
- Controles Gerenciales; son controles administrativos asociados al diseño e implementacion de la seguridad. Politicas de seguridad, procedimientos operativos estandar.
- Controles Operacionales; controles implementados por personas en lugar de sistemas. Guardias de seguridad, programas de concienciación.
- Controles Fisicos; Limitan el acceso fisico. Caseta de vigilancia, vallas, candados, lectores de credenciales.
Tipos de controles;
- Preventivo; limita el acceso de alguien a un recurso en particular. Por ejemplo implementar una regla de firewall, o una caseta de guardia que limite el acceso a las personas.
- Disuasorio; puede no impedir que alguien acceda a un recurso, pero lo puede desanimarlo o hacerlo pensar dos veces antes de un ataque. Por ejemplo un aviso que diga “solo personal autorizado”
- Detective; identifica o en algunos casos advierte cuando se a producido una determinada infraccion
- Correctivo; es algo que ocurre despues de que se ha detectado el evento. Por ejemplo una restauracion de datos luego de sufrir un ataque de ransomware
- Compensatorio; es algo que se utiliza de manera temporal para que todo siga funcionando despues de un incidente de seguridad. Por ejemplo la utilizacion de un generador de electricidad luego de haberse ido la electricidad
- Directivo; es ordenar a alguien que haga algo mas seguro en lugar de menos seguro. Por ejemplo indicar que los datos sensibles tienen que ser guardados en una carpeta protegida

1.2 Resumen de conceptos fundamentales de seguridad
Confidencialidad, Integridad y Disponibilidad (CIA)
- La CIA son los fundamentos de la seguridad informática. Confidencialidad: evita que alguien tenga acceso a información privada. Integridad: asegura de que lo enviado desde el origen llegue sin modificaciones al destino. Disponibilidad: asegura que los sistemas estén en funcionamiento en todo momento.
Non-repudiation
- es hacer que alguien no pueda negar haber realizado una acción o enviado un mensaje. Se hace con un hash para la integridad del mensaje y la firma digital con la clave privada para luego confirmarlo con la clave publica.
Authentication, Authorization, and Accounting (AAA)
Se parte con la identificación para afirmar ser un usuario en ese sistema. La comprobación de ese usuario y contraseña se conoce como Authentication. Luego determinamos el tipo de acceso (permisos) con la Authorization. Por último con Accounting tenemos un registro de todo lo que hace el usuario.
- Authenticating people; para acceder a un File Server le enviamos las credenciales a un VPN concentrator y este las reenvía a un AAA Server para que apruebe las credenciales y así el VPN concentrator autorice el acceso al File Server.
- Authenticating systems; se realiza mediante un certificado firmado digitalmente instalado en el dispositivo
- Authorization models; separa a los usuarios de la información mediante un modelo de autorización definidos por roles, organizaciones, atributos, etc.
Gap analysis
El análisis de brechas es un estudio de donde estamos vs donde nos gustaría estar, comparando los sistemas existentes, identificando debilidades y finalmente realizar un análisis detallado de lo encontrado.
Zero Trust
nada es confiable siempre se verifica.
- Plano de datos; es la parte del dispositivo que realiza el proceso de seguridad procesando y reenviando datos de una red a otra
- Plano de control; se configuran todas las acciones que ocurren en el plano de datos con políticas o reglas para determinar que hacer con los datos
- Adaptive identity; adicional a las credenciales, se verifica el contexto, el lugar de donde accede, tipo de conexión, etc.
- Threat scope reduction; limitando los lugares que se pueden acceder a la red
- Policy-driven Access control combina la identidad adaptativa con un set de reglas predefinidas
- Implicit trust zone; son zonas donde podríamos crear una regla donde indique si se conectan desde la red interna (zona de confianza) a un servidor interno es implícitamente confiable
- Policy Enforcement Point (PEP) todo el trafico que atraviesa la red debe pasar por el punto de cumplimiento de políticas para permitir o no el trafico según lo indica el administrador de políticas (Policy Administrator) que se comunica con el motor de políticas (Policy Engine) para tomar la decisión si se permite el trafico o no
Physical security
- Bollards; evitan que camiones o vehículos ingresen al área
- Access control vestibule (mantrap); un acceso donde la puerta tiene que estar cerrada para abrir la siguiente
- Fencing; es una valla o reja
- Video surveillance; cctv
- Security guard y Access badge; es alguien que verifica la identidad para la autorización de ingreso
Deception and disruption technology
- Honeypot atrae atacantes al sistema para ver el tipo de técnica que utiliza en nuestra contra
- Honeynets combina varios honeypots en infraestructura
- Honeyfiles son archivos que contienen información falsa
- Honeytokens es información rastreable para que en caso de que se copie o distribuye, saber de donde proviene
1.3 Explica la importancia de los procesos de gestión del cambio y su impacto en la seguridad
Business processes impacting security operation
- Approval process; En el proceso de aprobación primero se complete un formulario formal de proceso de control de cambios. Documentar el motivo que se necesita realizar el cambio. Identificar el alcance del cambio. Agendar fecha y hora del cambio. Identificar que sistemas se verán afectados por el cambio. Luego el comité de control de cambios analiza el riesgo asociado. Por ultimo la junta de control de cambios toma la decisión si se autoriza o no el cambio.
- Ownership; son los propietarios quienes gestionan el proceso pero lo realiza otra área manteniendo siempre informado al propietario.
- Stakeholders; las partes interesadas son las personas o departamentos que se verán afectados por el cambio que se propone
- Impact analysis reconocer que riesgos pueden estar implicados luego de realizar el cambio y se pueden asignar como riesgo alto, medio o bajo.
- Test results; es necesario realizar pruebas antes del cambio y se podría realizar en un entorno sandbox
- Backout plan; se necesita tener un plan de respaldo para volver a la configuración anterior al cambio
- Maintenance window; encontrar un tiempo para implementar el cambio sin afectar a la producción
- Standard operating procedure (SOP); documentar el proceso de control de cambios
Technical implications
- Allow list / deny list; en una lista de permitidos solo las aplicaciones detalladas en la lista podrán ser utilizadas y todo lo demás lo restringe. La lista de denegados es mas flexible ya que ejecuta todas las aplicaciones excepto las aplicaciones que fueron detalladas en la lista de denegados.
- Restricted activities; solo se realizarán los cambios indicados en el documento de control de cambios sin perjuicio de que se necesiten cambios adicionales para ejecutar ese cambio.
- Downtime; reservamos un rango de inactividad para realizar el cambio. En caso de que la organización opere las 24 horas es recomendable contar con un sistema secundario para poder habilitarlo y realizar el cambio en el primario
- Services Restarts and Application restart; es común que se necesite reiniciar el sistema, el servicio o la aplicación dependiendo del cambio que se realice
- Legacy applications; las aplicaciones heredadas son aquellas que ya no reciben soporte por parte del desarrollador
- Dependencies; primero se debe realizar un cambio en la aplicación o servicio antes de instalar o actualizar la otra aplicación o servicio debido a su dependencia
Documentation
Es común requerir documentación con el proceso de gestión de cambios para tener actualizado el conjunto de documentación esto incluye actualizaciones de diagramas o gráficos de la red o enumerar una serie de procesos, políticas o procedimientos.
Version control
Nos permite mantener documentación detallada de cambios en las configuraciones de routers, parches de SO o actualizaciones de una aplicación.
1.4 Explica la importancia de utilizar soluciones criptográficas adecuadas
Public key infrastructure (PKI)
es un conjunto de políticas, procedimientos, hardware, software, y persona que son responsables de crear, distribuir, administrar, almacerar y revocar procesos asociados a certificados digitales.
- Symmetric encryption; se utiliza la misma clave que se cifra para descifrar la información
- Asymmetric encryption; cifra y descifra con dos claves diferentes llamada publica y privada.
- Public key cryptography; son dos o mas claves relacionadas matemáticamente donde se cifra con una y se descifra con la otra.
- Private key; estas se mantiene privada y al cifrar con esta clave se busca confidencialidad y autenticidad
- Public key; cualquier persona podria tener acceso a esta clave y al cifrar con esta clave se busca la confidencialidad
- Key escrow; un deposito de llaves se puede almacenar local o un tercero para que en caso de que el trabajador se valla de la empresa aun podemos tener acceso a sus archivos cifrados
Encryption
Level;
- Full-disk and partition/volume encryption; utiliza cifrado a nivel de volumen o disco completo y en Windows se ocupa bitLocker y en mac FileVault
- File encryption; para cifrar un solo archivo en Windows se utiliza EFS (Encrypting File System) que está integrado con el sistema de archivos NTFS
- Database encryption; se puede utilizar el cifrado transparte donde encripta toda la información de la base de datos o parte de ella con clave simetrica
- Transport encryption; se utiliza cifrado al enviar datos a través de la red como por al utilizar el navegador se utiliza el HTTPS, o si necesitamos conectar personas de acceso remoto podríamos utilizar VPN SSL/TLS o entre 2 redes utilizar VPN IPsec
- Encryption algorithms; para un cifrado y descifrado exitoso, ambas partes deben utilizar los mismos algoritmos de cifrado
- Key lengths; para claves simétricas y asimétricas se recomienda contar con la mayor cantidad de bit para poder tener una clave fuerte
- Key Stretching; es realizar un hash del hash de la contraseña e incluso mas hash con el fin de fortalecer la contraseña. Se conoce como estiramiento o fortalecimiento de la contraseña
- Key Exchange; una forma de intercambiar claves simétricas es guardándola en una clave publica para que el receptor con su clave privada pueda abrirla y ver la clave simétrica o también utilizar algoritmos de intercambio de claves
Tools
- Trusted Platform Module (TPM); es un chip en la placa madre que proporciona funciones criptográficas
- Hardware Security Module (HSM); es un hardware que almacena todas las claves de los equipos en una organización
- Key Management system; es un Sistema donde podemos administrar todas las claves de la organización asociándolas a los usuarios
- Secure enclave; es un procesador dedicado y aislado encargado de procesar claves de cifrado del equipo
Obfuscation
Se oculta la información a la vista de todos
- Steganography; es cuando se oculta información dentro de una imagen, video, música o algún otro archivo.
- Tokenization; se toman los datos confidenciales y los reemplazamos con un token con números random para no ocupar los datos confidenciales
- Data masking; se oculta partes del numero original reemplazandolo por asteriscos * o algún otro digito mostrando por ejemplo asteriscos y luego 1234 de una tarjeta de crédito.
Hashing
puede ser llamado también resumen o huella digital. No es posible recrear los datos solo teniendo el hash. Podemos verificar integridad revisando el hash. Podemos utilizar el hash durante el proceso de la firma digital, y estas firmas digitales se utilizan para autenticación, no repudio e integridad. Una colicion de hash es cuando tenemos el mismo resumen con dos entradas diferentes. Las contraseñas deben ser almacenadas hasheadas.
Salting
es agregar información adicional a la contraseña para luego crear un hash de esa contraseña modificada para evitar ataques arcoíris.
Digital signatures;
los hash se utilizan durante el proceso de firma digital asegurando que el mensaje que se envió no fue cambiado gracias al hash (integridad). También la firma demuestra la fuente del mensaje (Autenticacion). Por ultimo al demostrar quien envió el mensaje provee el no repudio.
Blockchain
Esta tecnología se podría describir como un libro de contabilidad mayor donde todas las personas podrian tener una copia y una vez que ese libro agrega o modifica la información (bloques), todos los demás también lo pueden ver. Estos bloques tienen un hash que proporciona integridad
Certificates
Es un archivo que contiene una clave publica y una firma digital y en parte brinda seguridad informática al verificar que la persona o sistema es realmente quien dice ser gracias a la autoridad certificadora (CA). El formato estándar el certificado es el X.509.
- Root of trust; la raíz de confianza es el tercero que confía en el sitio y por eso también podría confiar yo
- Certificate Authorities; es la autoridad certificadora que firma digitalmente los certificados.
- Third-party; son todas las autoridades de certificación en las que le navegador confiara, lo que un sitio web podría comprar un certificado en cualquiera de esas autoridades y con eso nuestro equipo ya confiará en la pagina web
- Certificate signing request (CSR); esta solicitud de firma de certificado es donde juntamos la clave publica con la información de la empresa para luego enviar ese CSR a la CA para que pueda validar la informacion y así pueda utilizar la clave privada de la CA para firmar digitalmente el certificado y enviárnoslo
- Self-signed certificates; luego de haber habilitado una autoridad certificadora (CA) interna, ahora tenemos que instalar el certificado autofirmado en la cadena de confianza en los dispositivos para que confíen en cualquier cosa a la que se conecten
- Wildcard certificates; este certificado comodin o nombre alternativo del sujeto permite colocar el nombre de un dominio con asteriscos con el fin de que podamos tener subdominios habilitados dentro del nombre de dominio principial. Por ejemplo * mail.nombredelaempresa.com, * ftp.nombredelaempresa.com, etc.
- Certificate Revocation List (CRL); es una lista de todos los certificados que han sido revocados (dejar sin efecto)
- Online Certificate Status Protocol (OCSP); se conoce como grapado OCSP y este protocolo de estado de certificado en linea hace que cuando nos conectamos por primera vez a un servidor web ponemos el estado de nuestros certificados en los servidores web propios y así confirmar el estado de validez del certificado
Dominio 2.0 Amenazas, vulnerabilidades y mitigaciones
2.1 Compara y contrasta los actores de amenazas comunes y sus motivaciones
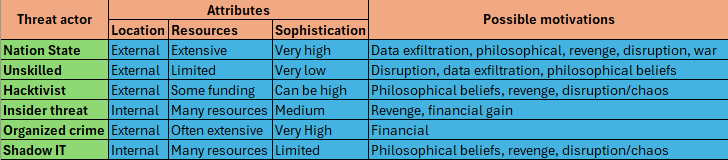
Threat actors
Un actor de amenaza es una entidad que es la causa de un evento que afecta la seguridad de otros
- Nation-state; puede ser un gobierno o una parte de un gobierno y las motivaciones pueden ser exfiltracion de datos, razones filosoficas o politicas, venganza, etc. Un gobierno cuenta con recursos masivos por lo que podrian realizar Amenazas Persistentes Avanzadas (APT) lo que podrian ser actores de amenazas bastante peligrosos.
- Unskilled attacker; son atacantes inexpertos que pueden ejecutar scripts sin tener conocimientos y sus motivaciones pueden ser disrupcion, exfiltracion de datos o razon politica o filosófica. Pueden ser internos o externos
- Hacktivist; pueden ser amenaza externa o interna y generalmente atacan con DDoS, modificaciones de sitios web o exfiltrar documentos importantes de la organizacion. No suelen contar con una gran cantidad de dinero
- Insider threat; es una amenaza dificil de localizar, pueden ser motivabas por venganza o dinero y tienen los equipos a su disposicion
- Organized crime; generalmente estan motivados por el dinero. Disponen de varios recursos y pueden tener una estructura corporativa
- Shadow IT; es cuando los trabajadores implementan cosas sin que el area de TI se entere. Por ejemplo podrian instalar un repetidor de wifi sin informar al area correspondiente
Attributes of threat actors
- Internal/external; los atacantes trabajan para su organizacion y estan dentro de la propia empresa o pueden ser de afuera de la organizacion intentando de obtener acceso a traves de distintos recursos publicos
- Resources/funding; pueden ser actores con pocos fondos y por esto es posible que tengan acceso limitado a los recursos, o con muchos fondos de dineros lo que significa que podrian realizar una serie de ataques diferentes
- Level of sophistication/capability; es util saber el nivel de sofisticacion de un atacante en particular o si tiene buenas habilidades creando sus propias herramientas
Motivations
para entender la motivacion de que alguien quiera realizar un ataque podria ser;
- encontrar datos y exfiltrarlos al publico
- espionaje
- interrumpir el servicio para crear problemas
- chantaje
- ganancias financieras
- creencias filosoficas/politicas
- etica
- venganza
- disrupcion/caos
- guerra
2.2 Explica los vectores de amenazas comunes y las superficies de ataques
Un vector de amenaza o vector de ataque, es el método que utiliza un atacante para obtener acceso a los sistemas
Message-based vector
- SMS
- Instant messaging (IM)
Image-based
File-based
Voice call
Removable device (USB)
Vulnerable software
- basado en cliente o sin agente (agentless)
Unsupported systems and applications
Unsecure network vectors
- Wireless; se recomienda utilizar el ultimo protocolo WPA3
- Wired; tanto para la cableada e inalámbrica es recomendable habilitar 802.1X, que es un protocolo de autenticación que se pide credenciales para poder conectarse
- Bluetooth
Open service ports
solo se deben abrir puertos necesarios
Default credentials
se deben cambiar las credenciales por defecto de los dispositivos
Supply chain
la cadena de suministro también podria ser una puerta para un vector de amenaza
- Managed service providers (MSPs); podrian entrar a nuestra organizacion mediante este tercero que nos realiza servicios de monitoreo por ejemplo
- Vendor
- Suppliers; mediante hardware falsificado
Human vectors/social engineering
- Phishing; hacer creer que algo es real pero en realidad no lo es y se realiza mediante algún enlace que simula alguna pagina web pero en realidad es fraudulenta
- Business email compromiso; podrían modificar ciertas letras del del dominio del correo para que la gente no note que es un correo fraudulento
- Typosquatting; es cuando en el enlace modificar ciertas letras para enviar a la pagina web fraudulenta igual a la oficial. Por ejemplo www.pagina7.cl a www.pag1na7.cl
- Pretexting; es cuando te tratan de contar una historia ya sea por vos o por correo para que les des acceso a lo que ellos quieren
- Vishing; es el phishing mediante la voz
- Smishing; phishing mediante SMS
- Impersonation; es la suplantación de identidad por parte del atacante por alguien que no es
- Watering hole attack; este ataque de abrevadero el atacante inyectará código malicioso en la pagina web que él sabe que te conectas muy a menudo y para prevenir este ataque solo se tiene que tener una buena defensa de la red en capas
- Misinformation/disinformation; esta técnica de ingeniería social se trata de difundir información incorrecta a otros ya sea con desinformacion o información errónea. En la desinformacion el atacante crea múltiples cuentas falsas para que estás puedan compartir la información
- Brand impersonation; los atacantes crean cientos de paginas con marcas reconocidas para que la gente entre a esas paginas creyendo que es la oficial
2.3 Explica los distintos tipos de vulnerabilidades
Application
- Memory injection; agrega código malicioso a la memoria de un proceso existente ocultando el malware dentro del proceso. Una forma mas común de inyección de malware se denomina DLL (biblioteca de enlace dinámico) Injection
- Buffer overflows; El atacante escribe mas de lo esperado en la memoria, lo que provoca que se desborda hacia otra área de la memoria. El desarrollador de la aplicación tiene que realizar la comprobación de los limites para evitar este tipo de ataque
- Race conditions; es cuando dos eventos ocurren al mismo tiempo en una aplicación y esta no tiene en cuenta que estas dos condiciones pueden estar operando al mismo tiempo. El desarrollador tiene que comprobar si esto puede ocurrir al momento de crear la aplicación
- TOCTOU (Time Of Check To – Time Of Use attack) es un ataque dentro de la condición de carrera de tiempo de verificación a tiempo de uso. En simple, el atacante manipula el sistema con su malware en el tiempo en que el programa verifica el acceso y que le llegue la respuesta para escribir su propia respuesta.
- Malicious updates; Debemos asegurarnos de que la actualización que estamos instalando venga realmente de la pagina o del proveedor oficial y confirmando la firma digital
Vulnerabilidades basadas en sistema operativo (OS)
Un sistema operativo debido a su gran cantidad de líneas de código siempre tiene vulnerabilidades por lo que siempre se descubren nuevas y debido a esto son los parches de actualizaciones de seguridad. Las buenas practicas antes de instalar un parche son;
- Planificar la actualización para lo antes posible
- Se recomienda realizar pruebas aisladas del parche antes de implementarlo en la organización
- Guardar los datos antes de reiniciar si lo requiere
- Tener una copia de seguridad en caso de que algo salga mal
Web-based
- Structured query Language Injection (SQLi); es un ataque de aplicación en el que el atacante inyecta su propio código en la información que se ingresa en la aplicación. Para evitar esto los desarrolladores deben realizar controles en el código para evitar ingreso de datos innecesarios durante una entrada normal. Hay muchos tipo de inyecciones de código como HTML, SQL, XML, LDAP etc.
- Cross-site scripting (XSS); el ataque scripts entre sitios. Es una vulnerabilidad en aplicaciones basadas en web que aprovecha la confianza del navegador hacia diferentes sitios web basándose en un ataque que utiliza JavaScript. Para protegernos de este tipo de ataques es importante nunca abrir enlaces de desconocidos, podria funcionar deshabilitar JavaScript, tener el navegador y las aplicaciones actualizadas y el desarrollados debe garantizar que no se pueda ingresar script a la aplicacion
- Non-persistent (reflected) XSS attack es cuando un atacante envía un enlace y el usuario lo abre y sin que se de cuenta el mismo usuario es el que ejecuta el código malicioso contra un sitio web de terceros con el fin de robar credenciales, ID de sesiones o cookies
- Persistent (stored) XSS attack el atacante en vez de enviar un enlace directo a un usuario hace una publicación en redes sociales con el fin de que las personas que abran el enlace y los lleve al navegador este estará ejecutando el código malicioso robando las credenciales y adicionalmente se podria indicar que automáticamente comparta el enlace del codigo malicioso en su feed.
Hardware
- Firmware; es el sistema operativo que se encuentra dentro de los dispositivos IoT y muchas veces ni si quiera sabemos qué sistema operativo tienen estos dispositivos, por lo que solo los fabricanctes de estos pueden actualizarlos o administrarlos
- End-of-life (EOL); este es un aviso del fabricante que en un tiempo mas el equipo no recibirá mas actualizaciones
- End of Service life (EOSL) significa que el fabricante ya no brindará mas soporte al dispositivo
- Legacy; un dispositivo heredado es cuando se utiliza un equipo donde ya no hay soporte pero aun así se sigue utilizando debido a que cumple una funcion muy importante para la organizacion. En este caso se recomienda utilizar reglas de firewall adicionales para el dispositivo y firmas IPS adicionales
Virtualizacion
- Virtual Machine (VM) escape; es un tipo de ataque donde luego de obtener acceso a la maquina virtual, el atacante salta a la siguiente maquina virtual dentro del hipervisor o al sistema operativo del host
- Resource reuse; Cuando no se administran bien los recursos del hypervisor como por ejemplo asignar mas memorias a las VM de las que el host cuenta, este podria escribir en un area de memoria donde la otra VM podria leer
Cloud-specific
algunos ataques a los servicios que podrian sufrir este tipo de tecnologias son ataques DoS debido a que se encuentra todo el servicio en la nube publica, ataques de authentication bypass en caso de tener accesos debiles a los servicios, recorrido de directorios (directory traversal) en caso de que las configuraciones no se encuentren bien establecidas, ejecucion de codigo remoto. Otros ataques que podria recibir son a las aplicaciones de la nube por ejemplo vulnerabilidades de aplicaciones web, Cross-site Scripting (XSS), escritura en memoria fuera de limites y por su puesto SQLi
Supply chain
Dentro de la cadena de suministro de alguna organizacion que manufacture equipos tambien podria tener vulnerabilidades ya que estos proveedores al conectarse con la empresa podria vulnerar la seguridad y así crear backdoors en equipos que ellos venden sin darse cuenta
- Service provider; cuando subcontratamos un servicio no sabemos cual es la seguridad que ellos tienen, por lo que nos afecta enormemente en caso de que este subcontrato tiene informacion confidencial de nuestra empresa. Debido a esto, es comun que las empresas realicen auditorias de seguridad continua de sus proveedores de servicios
- Hardware provider; podria ser un caso de que se compra un equipo de alguna marca reconocida pero ese equipo resulta ser pirata, por lo que no cuenta con la seguridad necesaria
- Software provider; al momento de adquirir un nuevo software es recomendable validar la firma digital del software. Tambien al momento de realizar la actualizacion se tiene que tener precaucion de realizarla directamente con la marca del software
misconfiguration
Existen varios casos donde se deja en internet datos que tendrian que ser confidenciales debido a que no realizacion la proteccion de estos. Tambien las cuentas de administradores muchas veces son no seguras, por lo que una buena practica es deshabilitar el inicio de sesion con la cuenta de administrador. La utilizacion de protocolos inseguros como por ejemplo Telnet, FTP, SMTP, IMAP, entre otros son fuentes de vulnerabilidades debido a que no cuentan con tecnologias de cifrado, por lo que se recomienda la utilizacion de las versiones seguras como SSH, SFTP, IMAPS, etc. Dejar los dispositivos con sus credenciales por defecto es otra fuente de vulnerabilidad que podriamos tener. Tener puertos y servicios abiertos sin que sean ocupados puede otorgarle acceso a los ciberdelincuentes
Mobile device
- Jailbreaking/rooting; reemplaza el firmware o sistema operativo por uno de terceros perdiendo todo el soporte de la marca del sistema operativo. Generalmente se realiza para eludir la seguridad del SO y habilitar nuevas funciones. Al realizarlo en el sistema Android se llama Rooting y en Apple iOS se llama Jailbreaking.
- Side loading; es la instalacion de aplicaciones fuera de la tienda oficial de la marca por lo que podria contar esa aplicacion con malware. Generalmente los SO de los dispositivos bloquea ese tipo de instalacion por lo que para realizar esto se realiza el Jailbreaking o rooting
Zero-day
son las vulnerabilidades que aun no se encuentran por parte de las empresas pero los atacantes ya las estan explotando, por lo que una vez que se enteran de esta vulnerabilidad la empresa creará el parche de seguridad con urgencia. Mientras aun crean el parche para la vulnerabilidad el atacante puede seguir explotandola y eso es un ataque Zero-Day.
2.4 Dado un escenario, analiza los indicadores de actividad maliciosa
Malware attacks
- Ransomware; infectan la maquina, cifran todos los datos y solicitan un pago para recibir la clave de descifrado
- Virus; es capaz de replicarse de una computadora a otra, pero para que se inicie se requiere la intervención humana iniciando un ejecutable o haciendo clic en algun enlace. Existe un virus sin archivo donde no se instala como software y lo que realiza es ejecutar comando en aplicaciones como PowerShell y con eso puede descargar scripts adicionales
- Worms; puede ejecutarse y autoreplicarse entre sistemas sin intervención del usuario. Se pueden miticar con Firewalls, IDS/IPS
- Spyware; es un malware que vigila todo lo que sucede en el sistema e incluso instalar un keyloggers. Puede poner publicidad, robar informacion personal, o cometer fraudes de afiliados para ganar dinero con las compras en linea. Muy similar a un virus necesita ser instalado. Puede ser mitigado con anti-virus o anti-malware
- Bloatware; Son programas o aplicaciones que vienen con el sistema ya instalados y que no queremos tener ya que no son ningun aporte y utilizan recursos innecesarios
- Keyloggers; es malware que guarda todas las teclas que se precionan para obtener informacion personal como contraseñas e incluso pueden sacar fotos de la pantalla para enviarlas al atacante
- Logic bomb; Está esperando que cierta hora y fecha o que el usuario realice cierta accion para que se active borrando datos, reiniciar el sistema, realizar cambios en el sistema. Son creados por un usuario final por lo que no es algun malware en sí y debido a esto no existen firmas de antivirus o antimalware para este tipo de ataque
- Rootkits; Generalmente se oculta en el kernel del sistema operativo lo que lo hace muy dificl de identificar y al ejecutarse lo hace como parte del sistema operativo por lo que posiblemente no se verá en la lista de procesos del sistema. Para combatirlos se crean procesos dentro de la BIOS UEFI llamado arranque seguro y este busca firmas del sistema operativo y verificará que nada haya cambiado en el kernel del SO antes de iniciar el sistema
Physical attacks
- Brute force; se puede usar la fuerza bruta para forzar cerraduras de puertas o ventanas para acceder a los sistemas fisicamente por lo que es recomendable tenerlo en consideracion
- Radio Frequency Identification (RFID) cloning; clonaciones de tarjetas de acceso a oficinas
- Environmental; Un ataque medioambiental muy comun es apagar la energia en un centro de datos o tambien apagar el A/C para que luego al sobrecalentarse los equipos estos se apaguen
Network attacks
- Denial-of-service; un atacante sobrecarga un servicio para que este colapse y los usuarios legitimos no lo puedan utilizar
- Distributed Denial of Service (DDoS); utilizan multiples dispositivos de todo el mundo para sobrecargar un servicio. Existen DDoS amplificados y reflejados que consisten en aprovechar los servicios de internet disponibles como NTP, DNS o ICMP donde con una pequeña solicitud a muchos servidores abiertos de DNS hacemos que estos respondan todos juntos a la IP de la victima
- Domain Name System (DNS) attacks; Puede ser un envenenamiento de DNS una modificacion del archivo host de la computadora victima para que la victima primero verifique si en ese archivo se encuentra la resolucion DNS en lugar de realizar la consulta en el propio servidor DNS. DNS spoofing/poisoning es cuando un atacante escucha una solicitud de DNS en tiempo real conectandose al servidor DNS y modificando la direccion de resolucion de DNS con la direccion IP del atacante fraudulenta. Domain hijacking (secuestro DNS) es cuando el atacante entra al servidor y realiza cambios en la configuracion del servidor DNS. URL hijacking (secuestro de URL) podria redirigir a los usuario a los usuario a un sitio web que presenta publicidad o tambien podria registrar un nombre parecido modificando solo una letra con el fin de que el usuario no se dé cuenta que se encuentra en otra pagina, este aprovechamiento del error ortografico se llama Typosquatting o Brandjacking
- Wireless attacks; la principal vulnerabilidad asociada al ataque de desautenticacion es que los marcos de administracion no proporcionan ninguna seguridad enviando todo en texto claro por lo que se podria ver informacion de los dispositivos. Gracias a la actualizacion 802.11ac varios marcos de administracion se encuentran cifrados como los anuncions de disociacion, autenticacion y cambio de canal. Radio Frecuency (RF) jamming (atascado) es cuando se envia interferencia para que el usuario escuche mas ruido que datos reales del punto de acceso inalambrico (AP). Wireless jamming tambien es un ataque que inabilita la red WiFi enviando ruido al AP
- On-path attacks; un ataque en ruta o man-in-the-middle permite a un atacante ubicarse entre dos dispositivos y observar todo el trafico que va y viene entre los sistemas, siendo un ataque invisible para las victimas. Un tipo de ataque en ruta es el envenenamiento de ARP (ARP poisoning o spoofing) y este se realiza al momento en que la computadora victima no conoce la direccion hardware (MAC) del enrutador victima y lo unico que tiene es la direccion IP del enrutador y es el Protocolo de Resolucion de Direcciones (ARP) lo que permite resolver la direccion MAC a partir de una direccion IP enviando un mensaje de Broadcast a la red preguntando si algun dispositivo es 192.168.1.1 y esperando la respuesta de la MAC de ese dispositivo y una vez con esa respuesta el PC guarda la IP y la MAC asociada en la tabla ARP. El ataque de ARP Spoofing es cuando el atacante envía su direccion IP indicando que él es 192.168.1.1 y con la MAC real del atacante lo que significa que cuando entre el router y la victima se necesiten comunicar todo el trafico pasará por el atacante y este luego de ver o modificar el trafico lo volverá a reenviar a su destino. On-path Browser attack o Man-in-the-browser el malware o troyano se configura como un proxy capaz de redirigir el trafico antes y despues de que se envie a la red, lo que significa que si la red estuviera encriptada igual se podria ver la informacion debido a que se ejecuta en el mismo dispositivo de la victima
- Credential replay; Un ataque de repeticion intercepta y retransmite un mensaje o una transmision de datos validas para engañara a un sistema o usuario. En este caso el atacante no necesita descifrar el mensaje ya que solo reutiliza la comunicacion legitima como credenciales de autenticacion o tokens para obtener el acceso. Un ataque de repeticion se llama Pass the Hash (pasar el hash) el hash se refiere al hash de la contraseña y es cuando un atacante obtiene una copia del hash en una autenticacion para luego hacerse pasar por la victima. Una forma de evitar este ataque es utilizar un cifrado para que no se pueda ver ningun trafico enviado a traves de la red junto con algun salt adicional a la contraseña, tambien configurar el servidor para no recibir el mismo hash dos veces. Las cookies de session son archivos que almacenan informacion sobre sitios que se visitan, nombres de usuarios y lo mas valioso para el atacante un ID de sesion con el fin de que con ese ID de sesion pueda obtener acceso al servidor sin las credenciales. Session hijacking (sidejacking) o secuestro de sesion ocurre cuando un usuario se autentica inicialemente con un servidor web con el usuario y contraseña y el server responde con un ID de sesion y si el atacante obtiene el ID de sesion podría usarlo para sesiones posteriores en el servidor web. Los ID session se encuentran en los encabezados por lo que podrian capturarse con Wireshark o Kismet. Tambien con exploits de XSS (Cross-site scripting). Una forma de evitar este tipo de ataques es cifrando todo configurando el servidor con HTTPS y en caso de poder tener esta conexion es recomendable cifrar con un concentrador VPN permitiendo el cifrado al menos en la primera parte del viaje de los datos quedando solo expuesta la parte que está despues del concentrador VPN
- Malicious code; El codigo malicioso podria estar empaquetado en un ejecutable, un script, macro virus, gusano, caballo de troya, o muchos otros metodos de codigo malicioso que pueden acceder al sistema. La defensa en crucial para evitar este codigo malicioso por ejemplo, utilizar un anti-malware para bloquear ejecutables, scripts o macro virus, un firewall para bloquear trafico malicioso, actualizaciones y parches continuos y capacitar a usuarios para que no sean victimas de phishing
Application attacks
- injection attacks; un ataque de inyección es una forma muy común de atacar una aplicación ya que el atacante puede agregar fácilmente codigo malicioso adicional a la entrada y pasa sanear esto se debe tener las comprobaciones adecuadas de cualquier entrada. Un ataque de inyección SQL es Inyeccion SQL y otros ataques son HTML, XML, LDAP, entre otros.
- Buffer overflows; el desbordamiento de búfer es cuando se ingresa mas información de la que una variable puede contener y los datos adicionales se desbordan en el bufer de memoria que se encuentra al lado de esa variable. Es evitable revisando las entradas de la aplicación
- Replay attack; un ataque de repetición es cuando el atacante recopila información directamente de la red o de la pc de la victima y reproduzca esa información en el servidor para obtener acceso adicional a la aplicación. Puede ser mediante una intervención de red (Network tap) o envenenamiento ARP (ARP poisoning) o malware en el pc de la victima. Una vez que recopila el hash de usuario y contraseña o el ID de sesión, puede usarlo para replicar contra el servidor y obtener acceso. Se podria utilizar un ataque en ruta (on-path) para la recopilación de información y un ataque de repetición (replay attack) para enviar esa información al servidor.
- Privilege escalation; puede ser una escalada de privilegios obtener acceso como administrador pero también puede ser una opcion para el atacante una escalada de privilegios lateral (horizontal). Para evitar este ataque es necesario cerrar cualquier vulnerabilidad del sistema, actualizar antivirus o antimalware con firmas de escaladas de privilegios.
- Cross-site requests forgery; este ataque de solicitud de falsificación entre sitios es cuando una vez que la victima inicia sesión en un sitio web, el sitio web confía en el navegador el atacante podria crear codigo que haga que su navegador una vez haya iniciado sesión en Facebook publique información en su estado. Una forma de evitar este tipo de falsificaciones es utilizar un token criptografico que se utiliza cada vez que el cliente realiza una solicitud
- Directory traversal; un recorrido de directorio es una vulnerabilidad asociada a la configuración incorrecta del servidor web lo que permite a un atacante leer o escribir archivos en un servidor web que normalmente están fuera del alcance
Cryptographic attacks
- Birthday attack; es la probabilidad de que se encuentre una colisión de hash mediante un proceso de fuerza bruta. Para evitar esta colisión es necesario utilizar un tamaño de salida de hash muy grande.
- Collision; es el mismo hash resultante de dos textos diferentes
- Downgrade attack; en un ataque de degradación el atacante intenta que 2 dispositovos utilicen un algoritmo de cifrado mas debil o que no utilicen cifrado derechamente. Una forma habitual de ataque de degradación es la eliminación de SSL (SSL stripping) combinando un ataque en ruta debido a que estas en medio de una conversación puedes realizar el ataque de degradación
Password attacks
- Spraying attack; el ataque de pulverización es un ataque donde se prueban las contraseñas mas comunes y en caso de no tener éxito pasaran a la siguiente cuenta con el fin de que no se bloquee la cuenta por muchos intentos fallidos
- Brute forcé; prueba muchas iteraciones diferentes de contraseñas hasta encontrar la correcta. Para evitar que la cuenta se bloquee en un ataque de fuerza bruta, los atacantes descargan el archivo que contiene la contraseña y a ese archivo se le hace la fuerza bruta.
Indicators of Compromise (IOC)
Es la evidencia de que alguien pudo haber violado o accedido a los sistemas. Por ejemplo una cantidad inusual de trafico de otro país, hashes modificados de archivos, cambios en los servidores de DNS, patrones inusuales de autenticación, etc
- Account lockout; un indicador muy revelador de una posible vulneración de seguridad es una cuenta bloqueada debido a demasiados intentos de inicio de sesión
- Concurrent sesión usage; el uso simultaneo de sesiones es cuando notamos que se encuentran logeados en dos dispositivos distintos con el mismo usuario
- Blocked content; los malware tienden a deshabilitar cualquier tipo de actualización de antivirus una vez que infectaron la maquina. Por lo que este es un buen indicio de indicador de vulnerabilidad
- Impossible travel; es cuando el mismo usuario se encuentra logeado en dos localidades distintas
- Resource consumption; cuando un atacante ingresa a la red y se encuentra por ejemplo transfiriendo archivos esto hará un consumo de recursos inusual y mas aun si esto ocurre en algún horario en donde los recursos son bajos (en la noche)
- Resource inaccessibility; no poder acceder a un recurso podria ser un indicador de compromiso por ejemplo al no poder acceder a un servidor puede ser posible debido a que están tratando de encontrar una vulnerabilidad y el equipo falló por lo que se encuentra inaccesible
- Out-of-cycle logging; un registro fuera de ciclo podria ser un indicador de compromiso al saber que ese registro o la información contenida en ese registro en especifico no debería estar en ese registro en ese periodo de tiempo. Por ejemplo el registro de una instalación de algún parche o programa en horario no autorizado es un registro fuera de ciclo lo que significa un posible indicador de compromiso
- Missing logs; los atacantes eliminan la información de log para ocultar que estaban en el sistema
- Published/documented; cuando los datos privados se encuentran disponibles en internet
2.5 Explica el proposito de las tecnicas de mitigacion utilizadas para proteger la empresa
Segmentation
Para limitar el alcance de cualquier tipo de evento de seguridad puede ser útil segmentar la red en pequeñas partes o para optimizar el ancho de banda de alguna aplicación
Access control
Una ACL proporciona una manera de permitir o prohibir el trafico a través de la red, sistemas operativos u otras tecnologías
Application allow list / deny list
Otra forma de segmentación es creando una lista de aplicaciones permitidas y denegadas garantizando que solo se puedan utilizar ciertas aplicaciones bloqueando las otras. Se encuentran dos filosofías diferentes para las listas de permitidos y para las listas de denegados. En las listas de permitidos solo se ejecutarán las aplicaciones que aparezcan en la lista denegando absolutamente todo lo que no se encuentre en dicha lista. En la lista de denegados se encuentra ingresado solo las aplicaciones que no se quiera que se instalen autorizando absolutamente todo lo que NO se encuentre en esa lista. El ingreso de los programas a las listas podria ser mediante un hash en vez de su nombre, lo que asegura que si algo cambia en la aplicación, cambiaria el hash por lo que la regla indicada se aplicaría. Tambien se pueden agregar mediante el certificado de cada aplicación o indicar que la aplicación se ejecute de algún directorio o ruta en especifico
Patching
Para evitar un ataque, la mejor manera es parchear cualquier vulnerabilidad conocida
Encryption
Otra forma de mitigar eventos de seguridad es limitar la cantidad de datos que un atacante podria obtener y esto se realiza mediante cifrado de archivos. En Windows el cifrado a nivel de archivo es llamado EFS y para cifrar discos completos se encuentra el cifrado de disco (FDE)
Monitoring
Para identificar eventos de seguridad, es importante tener un monitoreo constante y poder registrar toda la información que ocurre en la red. Es útil tener todos los archivos de registros en solo una fuente central llamado SIEM (Security Information and Event Management)
Least privilege
La practica del mínimo privilegio significa que los derechos y permisos asignados a un usuario están limitados al rol laboral especifico de ese usuario
Configuration enforcement
Reforzar la configuración de los sistemas que se conectan a la red donde normalmente se realiza al momento de conectarse y verifica si el sistema y antivirus está actualizado, entre otras cosas y se podria aplicar incluso a equipos de firewall y EDR. Tambien al momento de conectarse se podria verificar el status del certificado y así verificar si se debe o no confiar en ese dispositivo. En caso de no contar con los requerimientos aprobados se podria conectar a alguna VLAN especifica y así actualizar los cambios necesarios.
Decommissioning
Antes de realizar el desmantelamiento es necesario eliminar la información útil por lo que es recomendable destruir la unidad de almacenamiento
Hardening techniques
Una de las formas de mantener los sistemas operativos mas seguros es siempre realizar la actualizaciones de seguridad, contar un una política de seguridad que asegure que las cuentas de usuarios se encuentren protegidas con contraseñas complejas y limitar el acceso a las cuentas para que solo los necesarios tengan permisos de administrador.
- Encryption; cifrar los datos puntuales que se desean proteger es una buena técnica de protección mediante el Encrypting File System (EFS) de Windows o cifrar el disco completo con Full Disk Encryption (FDE). Para comunicaciones entre dispositivos a través de la red se podria cifrar todo el trafico de la red mediante una VPN o en muchas ocasiones las aplicaciones cuentan un un cifrado integrado como por ejemplo si hay conexión con otros dispositivos desde un navegador podria utilizar HTTPS.
- Endpoint protection; Se puede llevar a cabo gracias a Endpoint Detection and Response (EDR) ya que puede reconocer malware y vulnerabilidades conocidas basándose en una firma, analizar el comportamiento para identificar cuando puede estar ocurriendo algo malicioso, supervisar procesos, machine learning, analiza la causa raíz de las amenazas y tomar decisiones y medidas como por ejemplo aislar el sistema o poner en cuarentena la amenaza o revertirá a una configuración anterior para la eliminación de la amenaza
- Host-based Firewall; es un firewall basado en software que se ejecuta en segundo plano filtrando el flujo de trafico tanto entrante como saliente del sistema. Dado que se encuentra en el SO puede ver los datos antes o después del cifrado por lo que puede decidir que procesos debería aceptar o denegar. Supervisa los procesos desconocidos que podrian haberse asociado debido a algún malware y en caso de que detecte algo inusual puede bloquear automáticamente el trafico. Este firewall se ejecuta en sistemas individuales pero puede ser gestionado desde una consola central
- Host-based Intrusion Prevention System (HIPS); pueden al igual que un IPS buscar tipos de ataques pero a nivel de host. Tambien puede proteger las configuraciones de las aplicaciones y del sistema operativo, busca y verifica actualizaciones. Se puede basar en cambios de comportamientos, heuristica, firmas almacenadas, cambios en el registro, desbordamiento de buffer o cambios en carpetas de sistema operativo por lo que en cualquier de estos eventos podria alertar y bloquear el proceso
- Disabling ports/protocols; cerrar tantos puertos como sean posibles ya que cada puerto abierto es una posibilidad de que un atacante encuentre alguna vulnerabilidad. Se podria instalar un firewall de nueva generación para filtrar por servicios que utiliza el puerto
- Default password changes; es muy importante realizar el cambio de contraseñas que vienen por defecto en los dispositivos o programas
- Removal of unnecessary software; eliminar cualquier aplicación que no se encuentra en uso para reducir el riesgo
Dominio 3.0 Arquitectura de Seguridad
3.1 Comparar y contrastar las implicaciones de seguridad de diferentes modelos de arquitectura
Architecture and infrastructure concepts
- Cloud;
- REsponsibility matrix;
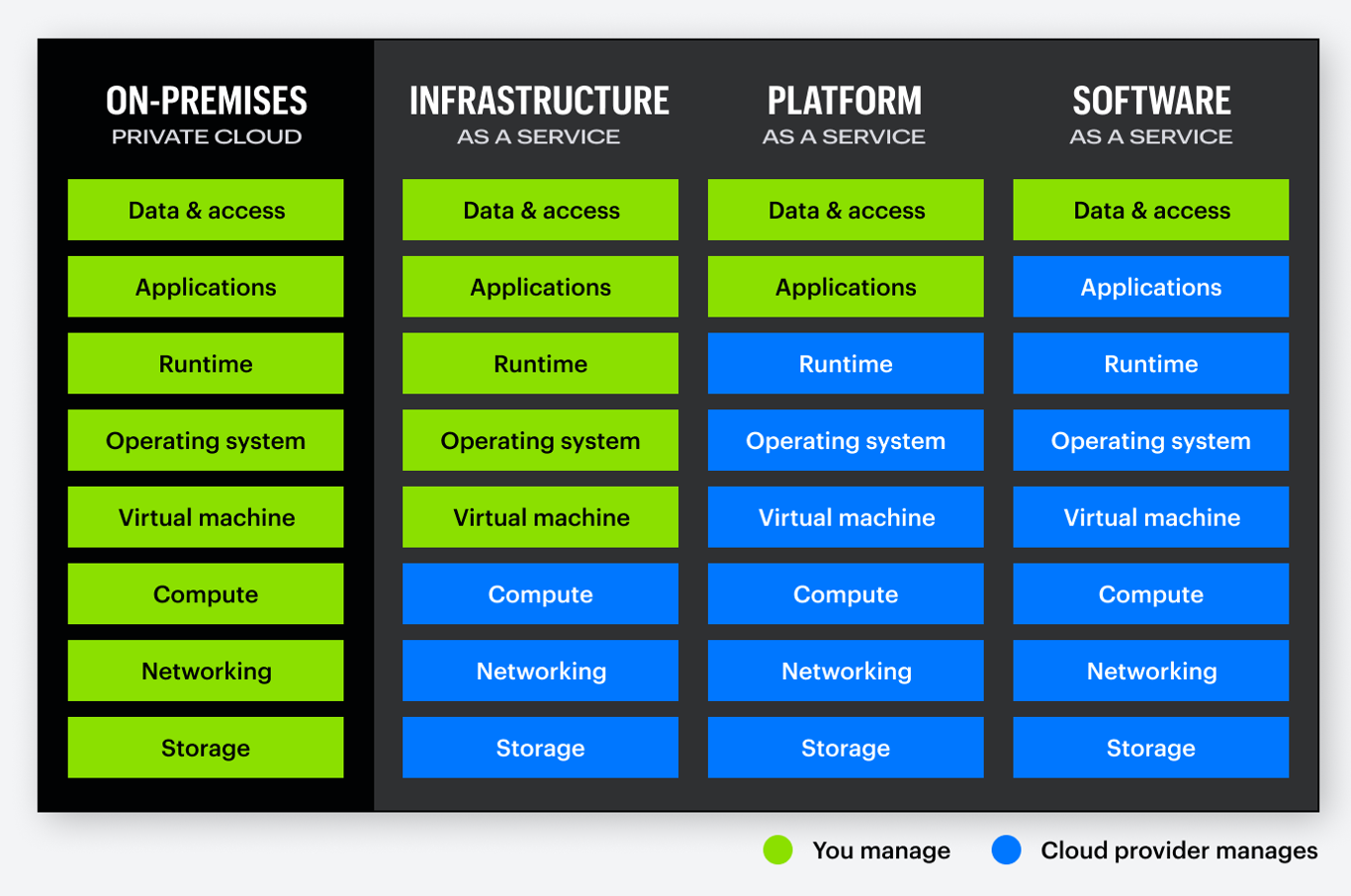
- Hybrid considerations; es cuando se utilizan nubes de distintos proveedores y es llamada nube hibrida y generalmente estos proveedores no se comunican entre si pero podría darse que los datos se transfieren entre las nubes por internet por lo que se tiene que considerar las configuraciones de seguridad para proteger los datos en transito
- Third-party vendors; una buena practica es contar con una política de gestión de riesgos de proveedores para poder administrar y mantener la seguridad de las tecnologías de terceros. También se debe pensar en como se manejarán la respuesta a incidentes para los proveedores externos y se debe monitorear estos procesos y dispositivos de terceros.
- REsponsibility matrix;
- Infrastructure as a Code (IaC); se crean instancias de la aplicación mediante código con el fin de que se pueda implementar rápidamente en otras nubes o modificar las instancias en el código directamente para realizar la modificación en la infraestructura rápidamente pudiendo crear la infraestructura completa en el código creado
- Serverless Architecture; son arquitecturas en la nube sin servidores donde solo se necesita acceder a funciones individuales (Function as a Service FaaS) que manejan una aplicación por lo que no nos preocupa el sistema operativo utilizado por lo que ahorra tiempo y dinero ya que solo se utiliza la función de una aplicación. Al tener el servicio en la nube se preocupa el proveedor de la nube de la seguridad
- Microservices and APIs; las APIs son interfaces de programación de aplicaciones donde nos permite controlar programáticamente la forma en que funciona una aplicación por lo que se puede dividir una aplicación entera en distintos microservicios para esa aplicación y ejecutarlos como instancias separadas en la nube. Con esto el cliente solo tiene que indicarle a la API Gateway para que esta envíe la solicitud al microservicio apropiado. Esto hace que sea escalable ya que solo se utilizarían servicios que se necesitan y no una aplicación entera, mas resistente ya que si un microservicio se pierde el resto seguirá funcionando y proporcionaríamos seguridad en función al microservicio, por ejemplo, si el microservicio maneja autenticación, proporcionaríamos un conjunto de procesos de seguridad para eso, o si está leyendo y escribiendo en una base de datos, habrá un proceso de seguridad asociado para ese microservicio.
- Network infraestructura;
- Physical isolation; este espacio de aire donde los equipos se encuentran separados sin ninguna conexion entre si se pudiera utilizar por ejemplo cuando se tienen los servidores web en un rack y los servidores de bbdd en otro rack y si se encuentra un espacio de aire entre ellos (sin conexion entre ellos) significa que hay aislamiento fisico.
- Logical segmentation; gracias a las VLANs permiten configurar ciertas interfaces en el switch a una VLAN y otras interfaces a otra VLAN, y de esta forma las VLANs no se pueden comunicar entre si, por lo que tiene el mismo efecto de tener 2 switches separados
- Software-defined networking (SDN); Los dispositivos de red tienen diferentes planos funcionales de operacion para dividir los dispositivos de red en funciones individuales y asi poder codificarlo y usarlo en la nube. Estos planos son;
- Plano de Datos / Capa de Infraestructura; es el proceso de reenvio de datos ya sea por switches, router, firewall, etc. Es decir el trafico de red.
- Plano de Control / Capa de Control; acá se gestionan el reenvio de datos del plano de datos. Por ejemplo la tabla de enrutamiento de un router para poder saber donde se tienen que reenviar los datos. En resumen este plano es donde se le indica al plano de datos como llegar del punto A al puento B (protocolos de enrutamiento dinamicos y estaticos).
- Plano Administrativo / Capa de Aplicacion; en este plano es donde se realizan cambios de configuracion del dispositivo ya sea mediante SSH, navegador o API

- On-premises security; es cuando la infraestructura se encuentra en la instalación y con esto se tiene un control total sobre las decisiones tomadas en materia de seguridad
- Centralized vs decentralized; en casi todas las organizaciones la tecnologia está descentralizada, debido a que se pueden tener varias sucursales, varios proveedores de servicios en la nube y mas de un sistema operativo ejecutandose en la organizacion, por lo que resulta algo complejo de gestionar. La mayoria de los profesionales de seguridad crean una vista de gestion consolidad de todos los sitemas desde una unica consola de monitoreo proporcionando una mayor visibilidad pero crea un unico punto de fallo.
- Virtualization; permite correr diferentes S.O. en el mismo hardware
- Containerization; algunas organizaciones están migrando a este tipo de virtualizacion llamada contenedores. Este servicio permite mantener multiples aplicaciones ejecutandose simultaneamente dentro del software del contenedor (Docker) sin la necesidad de tener multiples S.O.
- IoT (Internet of Things); son dispositivos diseñados para integrarse en la red y ser compatibles con algunas de las funciones y servicios que se utilizan a diario. El problema que su seguridad no es la mejor por lo que se tiene que tener en cuenta al momento de implementarlo.
- Industrial Control systems (ICS) / Supervisory Control and Data Acquisition (SCADA); este sistema permite a los tecnicos trabajar desde una sala de control centralizada, supervisar el estado de los equipos y realizar cambios y modificaciones desde la sala de control. Este sistema debe estar completamente segmetnadas del exterior.
- Real-time operating system (RTO); el sistema operativo en tiempo real es un sistema donde todo el sistema se centra en un unico proceso. Por ejemplo, al momento de frenar un vehiculo el sistema se centrará repentinamente en ese sistema de frenado, lo que se puede activar el ABS, los intermitentes, el ESP, etc.
- Embedded systems; un sistema embebido es aquel que tanto el hardware y software se crean como un dispositivo autonomo y diseñados para un proposito especifico, lo que significa que están diseñados para hacer solo 1 cosa y hacerla de manera eficiente, por ejemplo los semaforos, los smartwaches o equipos de monitoreo de un hospital
- High availability (HA); permite mantener un sistema en funcionamiento constante, incluso si falla una parte del mismo. Tambien llamado sistema redundante que es disponer multiples sistemas para que se pueda utilizar si algun sistema falla
Considerations
- Availability; la disponibilidad es que queremos que nuestros recursos se encuentren operativos el tiempo que se necesiten y a las personas adecuadas. Se mide en porcentaje del tiempo de disponibilidad durante un año. Por ejemplo, una empresa podria tener un 99,999% de disponiblidad en el año.
- Resilience; la resiliencia es el tiempo que demora en recuperarnos de una caida en los sistemas. Lo que es muy dificil saberlo con seguridad ya que todo depende del tipo de problema, por ejemplo, si el problema reside en un hardware debemos reemplazarlo por lo que no sabemos cuanto demorará ese reemplazo, o si el problema es de software no sabemos cuanto tomará instalar el parche de seguridad correspondiente. Una medida de resilencia es el MTTR que es el Tiempo Medido de Reparacion.
- Cost; siempre que elaboramos un plan para instalar una tecnologia especifica una de las primeras preguntas que nos hacemos es ¿Cuanto va a costar esto?. Se podria presagiar un costo inicial pero puede ser muy diferente al costo real total. Tambien se debe considerar el costo de mantenimiento y el costo por reemplazo o reparacion.
- Responsiveness; esperamos una capacidad de respuesta lo mas rapida posible. Es dificil de medir ya que pueden producirse varios pasos en una sola solicitud.
- Scalability; es comun tener un servicio o una aplicacion en donde se ajusta la carga actual y a medida que mas personas necesiten usarla podemos extenderla o escalar a una aplicacion mas grande.
- Ease of deployment; al implementar una aplicacion no solo hay que tener en cuenta la infraestructura tecnica, si no tambien recursos de hardware disponibles, disponer de presupuesto especifico y tener en cuenta el proceso de control de cambios. Para implementaciones basadas en la nube podria ser un proceso relativamente sencillo, ya que se puede automatizar mediante orquestacion que consiste en la creacion automatica de la infraestructura
- Risk transference; la transferencia de riesgo mas comun es la contratacion de un seguro de ciberseguridad contra la proteccion de ransomware lo que tambien podria activarse este seguro al sufrir periodos de inactividad empresarial y perdidas financieras. Este seguro ayuda a la empresa a minimizar el riesgo asociado a lo que sucede despues de un incidente de seguridad
- Ease of recovery; la facilidad de recuperacion es importante al momento de recuperarse de algun tipo de interrupcion ya que esto conlleva a un costo por perdida de funcionamiento, por lo que conviene planificar que el proceso de recuperacion sea lo mas eficiente posible. Por ejemplo luego de que un malware se aloja en un sistema operativo lo mas rapido es borrar todo y empezar de cero reinstalando el S.O. lo que podria tardar mas de 1 hora, o se podria tener imagenes del sistema operativo y recuperarte facilmente desde una copia de seguridad de la imagen que demoraria unos 10 min. En caso de implementar una nueva aplicacion o servicio se debe considerar qué se necesitará para poner en marcha este sistema si surge algun problema y encontrar la manera mas sencilla de recuperarse ante esta situacion.
- Patch availability; se debe probar y asegurar que los parches no dañarán nada que actualmente funcione en nuestra produccion para luego implementarlo en produccion lo mas rapido posible.
- Inability to patch; muchas veces hay sistemas como los HVAC que son los controles de calefaccion A/C y ventilacion que durante mucho tiempo no se encuentre alguna actualizacion con parches para alguna vulnerabilidad, por lo que es recomendable reforzar la seguridad en estos sistemas instalando un firewall entre ese sistema y la red empresarial.
- Power; es recomendable contratar un electricista autorizado para analizar el consumo electrico y que nos ofrezca planes para ampliarlo en el futuro y revisar la instalacion de UPS y generadores electricos.
- Compute; podria ser un unico procesador ejecutandose en un servidor o varios procesadores ubicados en multiples tecnologías basadas en la nube.
3.2 Dado un escenario, aplique principios de seguridad para proteger la infraestructura empresarial
Infrastructure considerations
- Device placement; se utilizan firewall para ayudar a segmentar la red y determinar donde instalar diferentes dispositivos en la infraestructura, junto con dispositivos Honeypots, jump server, balanceadores de carga, sensores también ayuda a crear un entorno mas seguro.
- Security zones; tiene un rango de IP diferente y así creando estas zonas de seguridad podríamos asociar la red según los dispositivos. Por ejemplo, separar una zona de confianza con una no confiable o una interna a una externa o detallarlas aun mas como por ejemplo zona interna, Internet, Servidores, bases de datos o cifrada. Con esta separación luego crearíamos reglas que indiquen por ejemplo que permitimos enviar datos desde una zona de confianza a una no confiable o permitir el acceso de una zona exterior de la red a la zona encriptada.
- Attack Surface; la superficie de ataque es por donde un atacante podria encontrar una vulnerabilidad, por ejemplo, un codigo de aplicación, un puerto abierto, un proceso de autenticación o un error humano. El objetivo es minimizar el tamaño posible de la superficie de ataque auditando codigo, bloquear puertos en el firewall, monitorear el trafico de la red en tiempo real, etc.
- Connectivity; es importante integrar la seguridad en la conectividad de la red ya sea protegiendo el cableado de la red, proporcionar cifrado a nivel de aplicación, para personas remotas o sitios remotos incluir cifrado con conexiones VPN y túneles IPsec.
- Failure modes; los dispositivos de seguridad que monitorean el trafico pueden fallar por lo que se debe saber como actuará la red una vez que esté afuera de línea el dispositivo de seguridad. Esto se podria ver en la documentación del equipo y los escenarios podrian ser;
- Fail-Open; que significa que en caso de fallo o queda inaccesible, los datos seguirán fluyendo a través de la conexión sin el proceso de seguridad correspondiente al dispositivo caido.
- Fail-Closed; en caso de fallo o inaccesible del dispositivo de seguridad, se interrumpirá la conexión de red y no habrá comunicación a través del enlace
- Device attribute
- Monitoring active vs passive; dado a que el IPS está diseñado para bloquear trafico malicioso en tiempo real, usa una configuración de monitoreo activo de forma predeterminada. Se puede utilizar un IPS como IDS (passive) solo monitoreando la red y esto se hace conectando un switch entre el IPS y los hosts. Con esta configuración el switch toma una copia del trafico (Port mirror) de los hosts y los envía al IPS para que solo monitoree el trafico de la red y no bloquee el trafico
- Network appliances;
- Jump server; un servidor de salto es un dispositivo situado dentro de la red que es accesible desde el exterior generalmente reforzado y con medidas de seguridad para limitar el acceso solo a personas autorizadas. Lo que significa que primero el cliente externo se conectará al Jump Server y desde el Jump Server podrá conectarse por SSH a un servidor web interno para realizar cambios.
- Proxies; un servidor proxi está diseñado para interponerse en una conversación entre dos dispositivos y realizar solicitudes de uno de esos usuarios. Lo que significa que cuando un cliente necesita por ejemplo una pagina web externa, en lugar de comunicarse directamente con el servidor web externo el host se comunicará con el servidor proxy y este realiza la solicitud a internet para que la respuesta se haga al servidor proxy y este pueda evaluar la respuesta y confirmar que la respuesta no es maliciosa para luego reenviarla al host solicitante. Tambien podria tener solo la función de almacenamiento en caché, filtrado de URL, escaneo de contenido. Generalmente hay dos tipos de proxy, el primero es proxy explicito que se configura en la aplicación o S.O. que se está usando donde se le indica el nombre del proxy o la dirección IP del proxy que se está comunicando y el segundo es el Proxy transparente que desde el punto de vista del cliente, no saben que está instalado y este puede intervenir en la conversación y realizar solicitudes en nombre del usuario sin necesidad de configurar nada en el S.O.
- Otro tipo de proxy es en NAT que convierte las dirección ip internas y externas en los routers. Un proxy de aplicación comprende los protocolos para una aplicación especifica, por ejemplo un proxy http, https, ftp, entre otros.
- Un proxy para controlar el trafico saliente a internet se llama “Forward proxy” o “Internal proxy” donde los usuarios realizan solicitudes al servidor proxy interno y este realiza la solicitud al sitio web de internet para que el sitio web responda al proxy y este verifique que sea legitimo para luego enviar esa respuesta web al usuario.
- Reverse proxy proporcionan un tipo de función similar pero para el trafico entrante a un servicio específico, por ejemplo usuario de internet que desean comunicarse con nuestro servidor web alojado en la red primero se conectan al servidor proxy y proxy realiza la solicitud en nombre del usuario luego el servidor web responde al proxy y el proxy envia la respuesta al usuario en internet proporcionando seguridad adicional delante del servidor web ya que si el proxy detecta algún trafico malicioso entrante este lo bloquea en lugar de ser enviado al servidor web y al mismo tipo el proxy puede actuar como servidor cache para solicitudes idénticas provenientes de internet.
- Open proxy es un proxy disponible para que cualquiera en internet pueda usarlo y así este servidor proxy realice las solicitudes que nosotros no queremos realizar.
- Intrusion Prevention System (IPS)/Intrusion Detection System (IDS) ; un Sistema de prevención de instrusiones está diseñado para observar el trafico que atraviesa la red en tiempo real y en caso de encontrar algo que podria interpretarse como peligroso o una vulnerabilidad explotable el IPS puede bloquearlo inmediatamente, en cambio, el IDS solo alerta que estas vulnerabilidades están atravesando la red sin poder bloquear el malware detectado
- Load balancer; toma una carga que viene de una dirección y la distribuye entre múltiples servicios para mantener la eficiencia distribuyendo la carga d emanera uniforme entre todos los dispositivos disponibles. Gracias a su tolerancia a fallos en caso de que se caiga un servidor el balanceador de carga reconoce esa caída y no se comunica con el servidor y dividirá la carga entre los servidores restantes.
- Active/Active load balancing significa que todos los servidores conectados al balanceador de carga están activos y están siendo utilizados por el balanceador.
- Active/Passive load balancing; significa que hay servidores a la espera de que falle un servidor activo y así se pueda balancear con ese servidor que no estaba siendo utilizado.
- Sensors and collectors; los sensores de los dispositivos como routers, switches, servidores, firewall entre otros tienen la capacidad de recolectar estadísticas y ponerlas a disposición de los recopiladores como los SIEM para la gestión y monitorización de redes y así poder consolidar, correlacionar y comparar diferentes tipos de datos en los diversos dispositivos
- Port security; Es la seguridad de las interfaces individuales que se encuentran en un switch o en las conexiones de un punto de acceso inalambrico, como por ejemplo si al conectarse en una red cableada o inalámbrica se solicita nombre de usuario y contraseña es un tipo de medida de seguridad
- Extensible Authentication Protocol (EAP) es el protocolo que permite la seguridad del puerto con un marco de autenticación ya sea en redes inalámbricas o cableadas (switches)
- 802.1X es un estándar IEEE que gestiona el proceso de autenticación de usuarios y dispositivos en la red también llamado Port-based Network Access Control (NAC) ya sea a la conexión de un puerto al switch como por WiFi, si no te autenticas no podrás acceder a la red mediante 802.1X lo que significa que EAP y 802.1X funcionan en conjunto para proporcionar credenciales de inicio de sesión y luego esas credenciales proporcionen acceso a la red. También se utilizan a menudo con otros protocolos de autenticación como RADIUS, LDAP, TACACS+, Kerberos, etc.
- Firewall Types; los Firewalls estan diseñados para controlar el flujo de trafico entre dos puntos, por lo tanto se puede controlar tanto el trafico que entra como el trafico que sale de la red.
- Network-based Firewalls; controlan el trafico basandose en la capa 4 de OSI (transporte) en cambio los NGFW se basan en capa 7 de OSI (aplicacion) por lo tanto, este ultimo puede permitir o denegar el trafico segun la aplicacion que se utilice en la red. Tambien los firewalls pueden dar servicios de encriptacion de trafico con una VPN y tambien pueden funcionar como un dispositivo de capa 3 (Router) por lo que suelen situarse en el perimetro de la red y controlar el flujo entre la red interna y la red externa.
- UTM / All-in-one security appliance; el gestor unificado de amenazas (UTM) es un tipo de firewall antiguo que pueden gestionar muchos servicios diferentes al mismo tiempo como URL filter / Content inspection, tienen cierta capacidad de bloquear malware y bloquearlo antes de que entre en la red, filtra Spam, Firewall, IDS/IPS, Router, Switch y modelador de ancho de banda para QoS y VPN endpoint. Pero la gran mayoria solo opera en la capa 4 por lo que solo toman el numero de puerto del protocolo y debido a su gran capacidad de servicios puede ser un problema por el rendimiento del equipo.
- Next-Generation Firewall (NGFW); o tambien llamado gateways de capa de aplicacion, dispositivos de inspeccion multicapa con estado o inspeccion profunda de paquetes, es un firewall de los mas modernos y operan en la capa 7 de OSI por lo que toman decisiones de reenvío en función de las aplicaciones que se utilizan y pueden reconocer quien envía el trafico, a donde se dirige, que contiene la capa de aplicacion del trafico y tomar decisiones sobre si ese trafico se permite o deniega. También tienen una lista de vulnerabilidades conocidas que pueden permitir o bloquear ese trafico convirtiéndolo en un IPS.
- Web Application Firewall (WAF); No funciona como un UTM o un NGFW ya que estan diseñados para analizar la entrada en aplicaciones web y permitir o denegar ese trafico en funcion de la entrada. Por ejemplo, este tipo de equipos pueden identificar inyecciones SQL dentro de un flujo de trafico y bloquearlas para que no lleguen al servidor de aplicacion web, por lo que no es raro ver un Firewall al lado de un NGFW ya que ambos analizan trafico diferente y toman desiciones de reenvío diferentes y muchas veces hay estandar de seguridad de datos como el PCI DSS que busca proteger la industria de tarjetas de pagos se centran en proporcionar firewalls de aplicaciones web para poder proteger estas aplicaciones basadas en tarjetas de creditos.
Secure communication/access
- Virtual Private Network (VPN); una VPN cifra todos los datos privados y los envia a traves de una red publica como internet. Suele gestionarse con un concentrador VPN y que actualmente se utilizan los NGFW para proporcionar la capacidad de punto final de VPN, tambien hay concentradores de VPN en Hardware y en soluciones de Software. En el cliente se tiene que instalar un software que puede conectarse y autenticarse en el concentrador VPN
- Tunneling;
- SSL/TLS VPN; usa el protocolo tcp443 al igual que ssl y se utiliza comunmente para la comunicacion de acceso remoto desde un solo dispositivo
- Site-to-Site IPsec VPN; con IPsec se puede crear un tunel cifrado entre ubicaciones remotas para que todos en un sitio remoto pueda comunicarse con la red corporativa remota y esto se debe a que entre las dos ubicaciones se encuentra un firewall con un concentrador VPN y estos firewall actuan como puntos finales de la VPN, por lo que como usuario no necesito ningun software ni configuracion adicional en ninguno de los dispositivos de ambas redes. A menudo se llama este tipo de configuracion como VPN de sitio a sitio
- Software-defined wide area network (SD-WAN); Red de area amplia definida por software es una forma relativamente nueva de WAN (red de area amplia) para conectarnos a aplicaciones basadas en la nube con el fin de poder conectarnos desde distintas sucursales de una empresa al centro de datos y tambien a la nube sin la necesidad de pasar primero por el centro de datos para que este se comunique con la nube. Es decir cada sucursal remota puede utilizar una conexion de red adecuada para conectarse directamente a la nube independiente del centro de datos de la organizacion.
- Secure access service edge (SASE); el borde de servicio de acceso seguro que podria ser la proxima generacion de VPN que permite comunicarnos con aplicaciones basadas en la web de forma mas eficiente y ademas todas las tecnologias de seguridad tambien estaran basadas en la nube como por ejemplo, QoS, routing, Zero Trust Network Access, Firewall as a Service, DLP DNS security, etc. Para luego instalar clientes SASE en todos los dispositivos para poder comunicarnos con la nube de forma segura y proteger los datos que atraviesan las redes.
Selection of effective controls
Algunas organizaciones utilizarán una o mas de estas opciones juntas como por ejemplo utilizar VPN de acceso remoto para la comunicacion con el usuario final y seguir utilizando VPN IPsec para todas las ubicaciones remotas, para proporcionar una conexion sin interrupciones para las aplicaciones basadas en la nube podria implementar SD-WAN y para brindar seguridad a las comunicaciones SD-WAN podria implementar SASE.
3.3 Compare y contraste conceptos y estrategias para proteger los datos
Data types
- Regulated; es cuando un tercero establece las reglas sobre como deben protegerse esos datos, por ejemplo si en la organización almacena información de tarjetas de créditos, los datos deben almacenarse de forma que cumplan con los estándares de la industria de tarjetas de pago. Tambien se debe tener en cuenta las leyes y regulaciones gubernamentales sobre como se deben almacenar los datos.
- Trade secret; se debe contar con la seguridad adecuada para los secretos comerciales que posee una organización.
- Intellectual property; la propiedad intelectual es un tipo de datos que a menudo otras personas pueden ver pero debemos proteger mediante derechos de autor y leyes de marcas registradas.
- Legal information; la información jurídica se encuentra gran cantidad de datos publicas pero hay algunos que deben permanecer privadas por lo que estos pueden almacenarse en un formato diferente y en distintos sistemas.
- Financial information; los detalles financieros se considerarían información confidencial
- Human readable; son datos que el humano puede leer y entender
- Non-human readable; son datos que los humanos no podemos entener como por ejemplo códigos de barras. Aunque hay formatos híbridos como códigos de barras donde abajo aparecen números que si se pueden leer
Data classificactions
- Proprietary; cualquier información que haya recopilado y convertido en su propio conjunto de secretos comerciales en una organización se considera información de propiedad exclusiva.
- Personally Identifiable Information (PII); son datos que pueden ser usados para identificar a algún individuo como nombre, fecha de nacimiento, nombre de famliares, datos biométricos, etc.
- Protected Health Information (PHI); la informacion medica protegida son datos de salud de cada individuo
- Sensitive; los datos sesibles podrian ser propiedad intelectual, PII, PHI.
- Confidential; son datos delicados que se necesitan acceso adicional para poder verlos.
- Public / Unclassified; son datos publicos o no clasificados que cualquier persona podria consultar.
- Private /classified / Restricted; se necesitan derechos y permisos adicionales o que se tendrían que firmar un acuerdo para tener acceso a los datos.
- Critical; son datos que siempre deben ser accesibles
General data considerations
- Data states;
- Data at rest; los datos en reposo son los que se guardan en algún dispositivo de almacenamiento con SSD, Hard Drive, flash drive, etc. Y aunque no estén cifrados siguen considerándose datos en reposo. Tambien se podria cifrar el disco completo, cierto fragmento de disco o ciertos archivos. A este tipo de datos se le pueden asignar permisos para limitar quien pueda tener acceso a esos datos en reposo.
- Data in transit; si se tranfiere información a través de la red nos referimos a datos en transito o datos en movimientos. Si los datos no están cifrados mientras viajan por la red no hay nada que los proteja de que alguien los intercepte. Una forma de proteger es con un firewall o un IPS para establecer políticas que permitan el paso del trafico legitimo e impidan que cualquier cosa desconocida o inusual atraviese la red. Para cifrar los datos en transito podríamos utilizar TLS o IPsec.
- Data in use; cuando los datos están en la memoria o están siendo procesados activamente dentro de la CPU les llamamos datos en uso y estos casi siempre estarán descifrados o en un formato no cifrado, ya que necesitamos poder ver los datos para poder realizar operaciones con ellos
- Data sovereignty; la soberanía de datos se refiere a la información que se almacena dentro de un país y por lo tanto todas las leyes y normas de ese país se aplicarían a esos datos.
- Geolocation; utiliza diversas tecnologías para determinar la ubicación de una persona y se puede usar esa información para determinar que tipo de acceso podria tener dicho usuario.
Methods to secure data
- Geographic restrictions; una forma de proteger los datos es establecer políticas sobre donde se encuentran los datos y donde podria encontrarse el usuario. A esto lo llamamos restricciones geográficas. Una forma de determinar la ubicación de un usuario es ver la subred que se encuentra conectado utilizando su dirección IP siempre y cuando esté conectado dentro de la organización. Esto se complica cuando el usuario se encuentra fuera de la organización por lo que podríamos pedir verificaciones adicionales como la geolocalización con GPS. Una vez verificando la ubicación del usuario se podria tomar decisiones sobre qué tipo de acceso tendrá el usuario y esto se llama Geofencing, por ejemplo, solo se accede a cierto tipo de datos si alguien accede dentro de la organización y si están fuera de la organización no debería tener acceso a esos datos.
- Encryption; es una forma de proteger los datos mediante el cifrado. Una vez realizado el cifrado notaremos que el resultado es muy diferente a los datos originales, y a esta diferencia lo llamamos confusión, ya que los datos cifrados presentan cambios drásticos a los datos originales
- hashing; es otra forma de proteger los datos y a veces es llamado huella digital o resumen de mensaje. Una característica del hash es que de su huella digital es imposible obtener los datos originales y es utilizado para almacenar password (confidencialidad) o verificar la integridad de algún archivo descargado. Tambien se podria utilizar el hash junto con la criptografía de clave publica para crear firmas digitales y así autenticar al remitente, otorgar no repudio y garantizar la integridad del mensaje
- obfuscation; es otra técnica de seguridad que ayuda a proteger los datos y lo que hace es que toma algo entendible y lo convierte a algo que es muy difícil de reconocer para los humanos.
- Masking; el enmascaramiento es un tipo de ofuscación donde enmascara los datos y lo que hace es que toma datos originales y los oculta para protegerlos como información personal o datos de tarjetas de créditos. Un ejemplo es cuando se paga con tarjeta de crédito la boleta enmascara los números de la tarjeta con asteriscos y solo muestra los últimos 4 dígitos de la tarjeta
- Tokenization; toma información confidencial y la reemplaza con un token, esto con el fin de no utilizar la información confidencial. Por ejemplo, al utilizar el teléfono como medio de pago de tarjeta de crédito en realidad estás utilizando un token temporal en lugar de transmitir el numero real de tu tarjeta de crédito. Esto se realiza por si alguien captura la información que se envia a través de la red, no podria reproducir ni reutilizar ese token ya que son de un solo uso. Lo interesante es que en esta técnica no hay algoritmo de cifrado,
- Segmentation; en lugar de tener todos los datos en una gran base de datos es y correr el riesgo del robo de esa base obtendrán toda la información, en cambio al segmentar la BBDD separará los datos en fragmentos mas pequeños guardando esa base en diferentes ubicaciones, lo que dificultaría el robo de todos los datos ya que tendría que vulnerar todos los sistemas donde se encuentran las bases de datos. Tambien con esto logramos establecer seguridad en las distintas bases de datos según la información guardada en cada una.
- Permission restrictions; un tipo de protección son las restricciones de permisos, lo que significa que cuando proporcionamos el nombre de usuario y contraseña hay una serie de derechos y permisos asociados a esa cuenta en particular.
3.4 Explica la importancia de la resiliencia y la recuperación en la arquitectura de seguridad
High availability (HA)
en esta configuracion todo estaria siempre en funcionamiento, encendido y disponible y si un sistema falla, tienes otro sistema funcionando al mismo tiempo y ese sistema asumirá la carga adicional y continuara brindando disponibilidad para ese servicio
- Server clustering; otra forma de proporcionar resiliencia es mediante la agrupacion de servidores configurando para que todos funcionen juntos como un unico servidor grande
- Load balancing; el balanceo de carga utiliza un balanceador de carga central para poder distribuir la carga entre los servidores individuales y a diferencia del server clustering donde cada servidor individual conoce a todos los demas servidores el balanceo de carga funciona de manera muy diferente porque cada uno de los servidores no tiene idea de que el otro servidor existe. El balanceador de carga actua como ese punto central que gestiona qué dispositivos reciben qué solicitudes y en caso de fallar un servidor el balanceador identificará automaticamente un servidor caido y lo eliminará administrativamente y seguirá distribuyendo entre los servidores restantes
Site resiliency
la resiliencia tambien la podemos extender a ubicaciones fisicas llamada resiliencia de sitio y es cuando disponemos de un sitio de recuperacion que haya sido asignado en caso de desastre donde todos tus datos estan sincronizados en ese sitio fisico y solo se está a la espera a que surja un problema y así cuando se declara un desastre la traslada todo su centro de datos a una ubicacion diferente separada de la zona afectada
- Hot site; es un tipo de sitio de recuperacion donde es una replica exacta del centro de datos ya que contiene todo el hardware que se utiliza en el centro de datos y mantenemos todas nuestras aplicaciones actualizadas en el sitio web principal y todos los datos se sincronizan con el sitio web principal con el fin de que se necesite trasladar todos los recursos al sitio de respaldo, este contendrá una replica exacta de nuestro centro de datos actual
- Cold site; un sitio frio significa que es un edificio vacio donde solo hay electricidad e iluminacion pero se necesitará traer todos los datos, todo el equipo y por su puesto todo el personal necesario para gestionar este sitio web en particular.
- Warm site; un sitio calido se trata de un intermedio entre un sitio frio y un caliente donde hay algun equipo y tal vez algunos datos disponibles pero necesitarás traer hardware adicional y datos adicionales para cubrir cualquier cosa que no está disponible en el sitio.
- Geographic dispersion; para la mayoria de las organizaciones su centro de recuperacion estará ubicado a una distancia considerable lo que significa que si ocurre algun incidente fisico en la ubicacion principal, es muy que el lugar de recuperacion no se vea afectado, por ejemplo, de tornados, huracanes, grandes incendios, etc.
Platform diversity
la diversidad de plataformas se utiliza para minimar la posibilidad de que una sola vulnerabilidad cause un problema en todos los sistemas operativos y por eso podria tener sentido utilizar diferentes sistemas operativos para diferentes propositos, por ejemplo, utilizar linux y windows en nuestro centro de datos y luego tener dispositivos macOS y windows en nuestros clientes para distribuir ese riesgo y quizas limitar la esposicion a una sola vulnerabilidad
Multi-cloud systems
es proporcionar residencia en la nube se tiene varios proveedores de nube para que cuando se produzca una interrupcion del servicio con un proveedor se podria tener servicios similares disponibles con otro proveedor
Continuity of operations planning (COOP)
la planificacion de continuidad de operaciones (COOP) es cuando una tecnologia no está disponible por alguna falla necesitamos encontrar la forma no tecnica de seguir prestando los mismos servicios, por ejemplo, tener un proceso manual para completar las transacciones y que las personas las firmen fisicamente o proporcionar recibos en papel en lugar de los recibos automatizados del sistema de ventas
Capacity planning
intentar predecir cuanta capacidad se puede necesitar para un servicio en particular es un desafio constante ya que si cometemos el error de no proporcionar suficientes recursos entonces tendremos demasiada demanda y en ultima instancia se produciran ralentizaciones en las aplicaciones o interrupciones del servicios y si construimos una infraestructura con un exceso de oferta, entonces hemos gastado mas dinero del necesario, por lo que la clave es crear la cantidad justa de oferta para poder satisfacer la demanda
- People; las personas tambien es un recurso dificil de aumentar o disminuir, ya que si se tiene pocos empleados tendremos que contratar a gente nueva y capacitarla, lo que requiere mucho tiempo y dinero. En caso de tener muchos empleados tendremos que trasladarlos a otras partes de la organizacion que necesite recursos adicionales o derechamente despedirlos.
- Technology; tambien tenemos que elegir una tecnologia que pueda escalar facilmente en funcion de la oferta y la demanda, ya que no todas las tecnologias tienen la capacidad de crecer y contraerse a medida que se presentan estas demandas, por lo que es importante pensar en ello en las primeras etapas del diseño de ingenieria
- Infrastructure; en caso de desarrollar una aplicacion, debemos pensar en todo el almacenamiento que necesitaremos, los servidores de aplicaciones, la conectividad de red y cualquier otra cosa necesaria para la aplicacion, y si esto se encuentra en nuestro centro de datos fisicos, probablemente necesitaremos comprar equipos adicionales que deberan ser enviados, configurarlos, instalarlos en el rack, probarlos y finalmente implementarlos en produccion. En la nube es un proceso de despliegue mucho mas sencillo, ya que con solo unos click en la consola de la nube, habras creado una nueva instancia de aplicacion, lo que hace aumentar facilmente la capacidad en la nube cuando hay momentos de mayor demanda
Recovery Testing
Las pruebas de recuperación suelen realizarse de forma regular para que todos comprendan el procesos y los procedimientos que se llevan a cabo en caso de un desastre real asegurándonos que para estas pruebas no afectará a los sistemas de producción real
- Tabletop exercises; una forma de minimizar los costos de una prueba de recuperación es seguir los pasos como si realmente los estuviera realizando y esto se denomina ejercicio de mesa y nos permite repasar los pasos que ya hemos descrito para el sistema de recuperación en un grupo de personas alrededor de una mesa y de esta manera podemos trabajar en todas las etapas de nuestra recuperación ante desastre y colaborar con otras personas de la organización para asegurarnos de que lo que estamos haciendo también se integra con sus planes de recuperación.
- Fail over; otra buena prueba de recuperación es una prueba de conmutación por error para comprobar si nuestras configuraciones redundantes son capaces de cambiar de sistema en caso de que se produzca un fallo.
- Simulation; también podríamos poner a prueba nuestra seguridad mediante simulaciones como por ejemplo, simulaciones de ataques de phishing o un proceso de restablecimiento de contraseña o intentar eliminar datos de la red para ver si nuestros sistemas automatizados los identifica
- Parallel processing; el uso de procesamiento paralelo nos permite tener multiples CPU o procesos que pueden utilizarse simultaneamente para procesar transacciones. Podria ser un unico dispositivo con multiples nucleos en su interior. Tambien proporciona un nivel de resiliencia ya que si uno de los procesadores quedara indisponible, aun podriamos distribuir la carga entre los procesadores restantes
Backups
una copia de seguridad permite recuperarte con relativa facilidad y a menudo muy rapidamente si alguna vez pierdes algun tipo de dato
- Onsite vs offsite; una copia de seguridad local es aquella en la que tanto los datos como el soporte de copia de seguridad se encuentran en la misma ubicacion. En cambio una copia de seguridad externa es cuando transferimos y almacenamos los datos a una ubicacion diferente. Muchas organizaciones utilizan el Onsite para almacenar informacion que pueda restaurarse muy rapidamente y podrian utilizar una copia de seguridad externa como opcion de almacenamiento a largo plazo
- Frequency; algunas organizaciones pueden realizar copias de seguridad cada semana, cada dia o hasta cada hora dependiendo de la cantidad de datos y su importancia.
- Encryption; la informacion que estamos respaldando puede tener informacion muy sensible o informacion privada, por lo que debemos pensar en como almacenamos esos datos y quien podria tener acceso a ellos. Una buena practica que realizan las organizaciones es encriptar toda la informacion que almacenan en una copia de seguridad. Al momento de relizar la copia de seguridad en la nube es necesario encriptarlo ya que no tienes idea de quien podria tener acceso a esta informacion.
- Snapshots: este tipo de backups se popularizó con el auge de las maquinas virtuales. Una imagen es un metodo de copia de sgeuridad muy comun para maquinas virtuales e infraestructuras basadas en la nube, permitiendo a un administrador de sistemas realizar una copia de seguridad completa de forma eficaz con tan solo pulsar un boton, sobre todo al querer realizar algun cambio en la maquina virtual, se toma la imagen y luego si se requiere se puede revertir los cambios con esa imagen
- Recovery testing; es muy importante probar las copias de seguridad para comprobar si puede restaurarlas correctamente y tambien probar que las aplicaciones funcionen de forma adecuada.
- Replication; esto permite copiar datos casi en tiempo real. Lo que significa que si realizan algun cambio en los datos locales, en cuestion de segundos o minutos esos cambios se propagaran a todos los sitios replicados. Lo que significa que siempre habrá una copia en tiempo real de esos datos ubicados en otros lugar y que podrian ser utilizados como copia de seguridad.
- Journaling; es muy preocupante al momento de escribir informacion en una unidad como disco duro externo se pierda la electricidad en medio del proceso, lo que significa que algunos datos se escribirán en el disco externo y otros se perderan, lo que podria hacer que los datos queden en un formato inutilizable. Para evitar esto, algunas aplicaciones tendran sus propios metodos para realizar el registro en el diario. El registro en diario funciona escribiendo primero los datos en un diario que se almacena en el disco externo y una vez redactado el diario, esa informacion se puede copiar en la version final de eso datos, y en caso de tener un corte de energia en medio de la escritura en el diario se perderán esos datos de escritura pero como no se escribió ningun dato este no es dañado y la escritura del diario se puede consultar en las escriturar anteriores y de ahí se actualizará la informacion que falta
Power resiliency
- uninterruptible Power Suplly (UPS); tienen baterias u otras fuentes de energia que nos permite seguir funcionando cuando el suministro electrico principal deja de estar operativo. Tambien nos ayuda en la baja tensión y la sobretensión. Existen UPS de gama baja que son utilizados como sistemas de reservas o llamados tambien fuera de linea. Un UPS interactivo puede aumentar gradualmente la cantidad de voltaje si se produce una baja de voltaje. Por ultimo estan los UPS On-line o de doble conversión
- Generators; proporciona electricidad de reserva a largo plazo ya que mientras se tenga combustible, este podrá alimentar la instalacion dependiendo de su capacidad. Generalmente se utilizan las UPS para que los equipos tengan energía mientras se inicia el generador ya que podria tomar algun par de minutos
Dominio 4.0 Operaciones de Seguridad
4.1 Dado un escenario, aplique tecnicas de seguridad comunes a los recursos informaticos
Secure baselines
al momento de implementar una nueva aplicación, se deben considerar todas las medidas de seguridad asociadas con su uso, por ejemplo, una posible configuración nueva en el firewall para asegurar que esa aplicación sea lo mas segura posible, asegurar que la aplicación esté actualizada y también el S.O. de donde se ejecuta la aplicación debe estar seguro. Es decir que cada vez que se implemente una aplicación, debemos asegurarnos que todas estas medias de seguridad básicas también se implementen junto con ella, por lo tanto siempre tenemos que comprobar que estas medidas de seguridad siguen vigentes y seguirán protegiendo la aplicación
- Establish baselines; el conjunto de líneas bases de seguridad vienen por parte de los fabricantes por lo que solo se podria modificar o cambiar para satisfacer las necesidades según sea la organización. Por ejemplo ponernos en contacto con el desarrollador de la aplicación y él podrá proporcionarnos una base de referencia que haya creado, que puede ser permisos de archivos almacenados y ajustes de configuración dentro de la aplicación. Windows también tiene una serie de líneas bases de seguridad para sus sistemas operativos donde incluyen kit de herramientas de cumplimiento de seguridad o SCT.
- Deploy baselines; una vez compilado esta lista de configuraciones de seguridad que se asociarán con la aplicación, el sistema operativo y cualquier otra parte de la instancia de la aplicación, ahora es el momento de aplicar esos ajustes a todos esos componentes, ya sea desde una consola central como en SCT, pero otras configuraciones pueden requerir procesos y configuraciones adicionales, como por ejemplo a través de la directiva de grupos de Active Directory, o realizar algún proceso automatizado para implementar las líneas bases mas fácilmente.
- Maintain baselines; Muchas de estas medidas básicas de seguridad son practicas recomendadas que una vez implementadas rara vez cambiarían, pero habrá ocasiones en las que necesites actualizar la línea base de seguridad
Hardening targets
Cuando se instala un S.O. la configuración predeterminada es rara vez segura, por lo que se deberá proporcionar configuraciones adicionales para aumentar la seguridad del sistema operativo. Muchos fabricantes crean guías de Hardening especificas para la aplicación o S.O. o en otros casos un tercero crea una guía y lo comparte con la comunidad
- Mobile devices; los fabricante lanzan parches para corregir errores y muchos de ellos incluyen actualizaciones de seguridad, otra técnica común de protección es segmentar los datos almacenados en los dispositivos móviles, generalmente en las empresas hay un segmento reservado para los datos de la empresa y otro segmento reservado para los datos del usuario proporcionando una segmentación logica entre la informacion personal y la informacion que podría ser propiedad de su empresa con el fin de que el atacante accede a uno de esos segmentos, no necesariamente tendrá acceso a ningun otro datos en ese dispositivo. Para administrar un grupo de dispositivos se podria realizar con un Administrador de Dispositivos Moviles (MDM) para poder supervisar los equipos.
- Workstations; reciben actualizaciones periodicas como correcciones de errores y parches de seguridad donde se aplican al propio sistema operativo, aplicacion o firmware del equipo. Generalmente las empresas lanzan los parches cierto dia del mes. Es recomendable eliminar cualquier software que no se esté utilizando en el equipo
- Network infrastructure devices; se debe reforzar la seguridad de los switches, router, firewall y otros. Una practica comun es cambiar las credenciales predeterminadas. En general los parches no se actualizan con tanta frecuencia.
- Cloud infrastructure; muchas empresas tienen un equipo especialmente destinado para administrar la nube de forma centralizada, por lo que el equipo tiene acceso a los sistemas basados en la nube, lo que requiere que esa estacion de trabajo sea segura. En la nube tambien tenemos que utilizar el minimo privilegio configurando las aplicaciones y dispositivos en la nube para que solo tengan el acceso minimo necesario para realizar su funcion. Es util tener instalado el sistema de deteccion y respuesta de Endpoints (EDR) para supervisar posibles ataques y confirmar que estén actualizados con las ultimas tecnologias antimalware.
- Servers; debemos asegurarnos de reforzar la seguridad de todos los servidores, mantener actualizado el S.O. Utilizar una contraseña compleja, establecer privilegios mínimos y deshabilitar cuentas que no se utilicen. En caso de que se pueda, establecer politicas dentro del propio servidor o el firewall para indicar la cantidad determinadas de dispositivos, y tambien deben contar con EDR, antivirus-antimalware, etc.
- ICS/SCADA; es una combinación de conectividad de red y plataformas que gestionan, supervisan y controlan todos los dispositivos industriales como generación de energía, industrial, petroleras, etc. Estos sistemas utilizan un sistema de control distribuido para proporcionar información en tiempo real sobre el rendimiento del sistema y supervisar el proceso continuo del dispositivo. Estos dispositivos se encuentran en su propia red aislada por un espacio de aire por seguridad, por lo que el acceso es muy limitado y nulo a través de internet.
- Embedded systems; los sistemas integrados tienen su propio S.O. ejecutandose dentro de un aparato diseñado especificamente para ello, por ejemplo un smartwach, televisores y electrodomesticos especializados. Estos dispositivos rara vez se le presentan parches de seguridad, por lo que si está disponible un parche, se debería instalar lo antes posible. Es recomendable plantearse la aislación de estos dispositivos en una red segmentada y proporcionar seguridad adicional como un firewall delante de esa red.
- Real-time Operating system (RTOS); son equipos que cuentan con sistemas operativos en tiempo real y tienden a ser deterministas, lo que significa que existe una cierta expectativa de plazos de tiempo para que cada proceso ocurra en esos sistemas, por ejemplo el sistema ABS de un vehículo es un RTOS ya que todo se centra en el funcionamiento de ese sistema en particular por cierta cantidad de tiempo. En caso de tener un dispositivo RTOS en la red, es recomendable un cortafuegos independiente o una tecnología basada en host
- IoT; Los fabricantes de sistemas IoT no son necesariamente expertos en ciberseguridad, por lo que es recomendable añadir un sistema de seguridad y segmentar estos dispositivos en su propia red de IoT.
Wireless Devices
- Installation considerations; si se encuentra con problemas en una red inalámbrica es recomendable realizar un un estudio de cobertura mediante un mapa de calor para ver la intensidad de la señal en el lugar
Mobile Solutions
- Mobile Device Management (MDM); muchas organizaciones gestionan sus dispositivos móviles mediante el uso de gestos de dispositivos (MDM), este gestor puede implementar ciertas políticas o exigir que ciertas aplicaciones estén siempre instaladas en esos dispositivos. Tambien se pueden realizar políticas sobre que funciones del dispositivo se puede utilizar, como por ejemplo, la cámara del teléfono del teléfono cuando estés dentro de la organización y cuando salga se pueda activar y también permite segmentar los datos de la empresa con los datos personales del usuario.
- BYOD; “trae tu propio dispositivo” es cuando un empleado trae su teléfono personal para usarlo tanto para fines personales como laborales y se pueden administrar desde el MDM y se debe asegurar cuando el usuario se venda el celular para eliminar correctamente la información de la empresa.
- Corporate-owned, personally enabled (COPE); la propiedad corporativa, habilitada personalmente significa que la empresa compra el dispositivo móvil y lo asigna a los empleados de su organización. Este dispositivo COPE podria reservarse exclusivamente para uso corporativo, pero muchas organizaciones también permiten que sea de uso personal.
- Choose your own device (CYOD); elige tu propio dispositivo es cuando el dispositivo sigue siendo de la organización pero le dan al usuario la posibilidad de elegir qué tipo de celular corporativo desea recibir.
- Connection methods;
- Celular; los teléfonos móviles tienen una gran movilidad que funcionan con estándares 4G y 5G y están distribuidas en diferentes áreas geográficas y esas áreas son “Cell”. Como no tenemos control total sobre los datos que envían y reciben en los celulares nos preocupa la monitorización del trafico, o incluso que alguien pueda rastrear la ubicación de otra persona. Por lo que mantener las actualizaciones y parches para esos equipos es fundamental para mantener la seguridad.
- Wi-Fi; presentan problemas similares. Lo ideal seria que todas las redes a las que nos conectaremos estuvieran cifradas, pero esto no ocurre cuando se conectan a una cafetería o un Hotel por lo que se debe asegurar tener disponible una VPN u otra tecnología de cifrado ya que un atacante podria monitorizar el trafico poniéndose en medio de la conversación con un Men in the Middle, o realizar un ataque de denegación de servicio.
- Bluetooth; o PAN nos da flexibilidad pero un dispositivo bluetooth podria acceder a los datos del dispositivo móvil, es por eso el emparejamiento formal cuando se conecta la primera vez a un dispositivo bluetooth, por lo que es importante no conectarse de forma automática a dispositivos desconocidos.
Wireless security settings
- Wi-Fi Protected Access 3 (WPA3); fue introducido el 2018 en reemplazo del WPA2 para evitar los ataques de fuerza bruta donde se creó un nuevo modo de cifrado llamado Protoclo de Modo Contador Galois (GCMP) que es mas potente que el de WPA2. GCMP incluye confidencialidad de datos mediante el cifrado asociado al protocolo AES y cuenta con una comprobación de integridad del mensaje. Tambien el proceso de autenticación y el protocolo de handshakes han sido completamente modificados en esta nueva versión de WPA, lo que incluye la autenticación mutua tanto para el dispositivos cliente como para el punto de acceso y las claves de sesión compartidas se crean en los dispositivos finales en lugar de enviar hashes de esas claves a través de la red. Como ya no hay handshakes de 4 vías el hash de la clave de sesión no se envía a través de la red por lo que no hay ataques de fuerza bruta. Este nuevo método para derivar las claves de sesión compartidas en WPA3 se denomina autenticación simultanea de iguales o SAE y utiliza una derivación del intercambio de claves Diffie-Hellman y con esto no solo puedes obtener esa clave compartida en ambos lados, sino que también puedes agregar un componente de autenticación. Cada usuario de la red inalámbrica recibe una clave de sesión diferente, por lo que, aunque todos utilicen la misma clave precompartida, no podrán ver el trafico de otros usuarios de la red. Este nuevo método de intercambio de claves está incluido en los últimos estándares IEEE
- Wireless authentication methods; por lo general se utilizan uno de dos métodos diferentes para la autenticación que son; la clave precompartida que hablamos anteriormente (PSK) que se podria utilizar en clasa (contraseña de red inalámbrica), y el otro método que se utiliza generalmente en las empresas es la autenticación centralizada, también conocida como 802.1X donde se pide el nombre de usuario y contraseña y quizás algún otro tipo de factor de autenticación.
- Wireless Security Modes; Open system o None significa que no require autenticacion ni ningun tipo de seguridad en esa red inalámbrica. WPA3-Personal / WPA3-PSK con esta configuración todos utilizan la misma clave precompartida con una longitud de 256-bit. WPA3-Enterprise / WPA3-802 lo que significa que el punto de acceso inalambrico solicitará un usuario y contraseña, y la autenticación generalmente está vinculada a un servidor de autenticación centralizado que ejecuta RAIUS, LDAP o TACX.
- AAA Framework; Un servidor de autenticacion centralizado suele llamarse Servidor AAA, este marco AAA comienza con la identificación de la persona que intenta conectarse a la red (identificación) que por lo general se basa en su nombre de usuario. Luego se comienza con la AAA, donde la Authentication se trata de una combinación del nombre de usuario con la contraseña. La Authorization significa que una vez que obtienes acceso a la red se debe mostrar o acceder solo a los recursos autorizados que tiene la persona. Por ultimo el Accounting es todo el registro de la sesión por ejemplo la hora de inicio de sesión, cantidad de datos enviados y recibidos y la hora de cierre de sesión.
- Remote Authentication Dial-in User Service (RADIUS); el servicios de usuario de autenticación remota es un protocolo de autenticación muy popular y lo que hace es que cada vez que se conectan a un router, switch o firewall para realizar cambios de configuración, iniciar sesión en un servidor o acceder a una VPN donde tienen que proporcionar un nombre de usuario y contraseña, estas se comparan con un servidor AAA que puede ser un servidor RADIUS.
- IEEE 802.1X; la solicitud de nombre de usuario y contraseña que recibimos lo proporciona el estándar 802.1X y también se conoce como Control de Acceso a la Red o NAC e impide que cualquiera acceda a la red a menos que primero proporcione sus credenciales. Esto aplica tanto para redes inalámbricas como cableadas y se usa comúnmente junto con el servidor AAA. Por lo que se necesita un servidor RADIUS, un servidor LDAP y un servidor TACACS+ para poder consolidar todas las credenciales y poder acceder a ellas desde muchos dispositivos diferentes. Al tener todo centralizado en el servidor AAA permite funcionalidades de gestión adicionales, por ejemplo si alguien deja la organización, simplemente se desactiva su cuenta y ya no tendrá acceso a la red.
- Cryptographic protocols; EAP (Extensible Authentication Protocol) es uno de los protocolos utilizados en 802.1X y es un marco que nos permite incorporar la autenticación dentro del proceso 802.1X y suele involucrar tres servicios diferentes pudiendo estar en tres dispositivos diferentes.
- Authentication protocols; el dispositivo uno es el Supplicant (Solicitante) que es quien intenta iniciar sesión en la red, el segundo es el autenticador que normalmente es el dispositivo al que te quieres conectar y luego hay un servidor de autenticación o servidor AAA en el backend donde autoriza si con las credenciales enviadas puede ingresar
Application security
Muchos de los problemas de seguridad se encuentran en el código de la aplicación y se detectan en el control de calidad (Quality Assurance QA) y normalmente hay un proceso de pruebas donde no solo se prueba la funcionalidad de la aplicación, si no que también una serie de comprobaciones de seguridad.
- Input validation; los desarrolladores de aplicaciones suelen realizar la validación de entrada cuando se introduce información en su aplicación, garantizando que cualquier dato inesperado que se introduzca no será interpretado por la aplicación. Los Fuzzers son procesos automatizados para proporcionar diferentes tipos de datos de entrada para las aplicaciones, para ver como se comporta la aplicación.
- Secure cookies; las cookies son pequeños fragmentos de información que se almacenan en el navegador y ayudan a proporcionar información de seguimiento para los sitios que se visitan y también son responsables de mantener la sesión una vez que se inicia sesión en un sitio web. La cookie es solo un archivo de datos, pero la información podria proporcionar a un atacante detalles valiosos. Es por esto que muchos navegadores utilizan cookies seguras, lo que significa que hay un atributo especial establecido que requiere que solo se transfiera si se utiliza HTTPS o una conexión cifrada. Los desarrolladores de aplicación generalmente no incluyen información confidencial en las cookies, por riesgos a ser vistas por terceros.
- Static code analyzers; para probar la seguridad de las aplicaciones se realiza un proceso de análisis estático de codigo que es llamado Static Application Security Testing (SAST), esta prueba de seguridad de aplicaciones estáticas hace que los desarrolladores introducen su codigo en el analizador estático y este lo examinará para intentar encontrar vulnerabilidades como Buffer Overflows, Database Injections, etc. Existen problemas de seguridad que no se pueden detectar simplemente examinando el codigo, por ejemplo, puede haber criptografía incluida en la aplicación que hace que se cree una vulnerabilidad y este tipo de problema de seguridad probablemente no será detectado por un analizados estático. Tambien puede ser que el resultado del analizador tampoco sea del todo preciso, por lo que el desarrollador tiene que revisar la salida del analizador.
- Code signing; con la firma de codigo verificamos que el codigo que estamos instalando sea el que envío el fabricante o el desarrollador de la aplicación. Con la firma de código también verificamos si acaso ha sufrido cambios la aplicación desde que dejó de estar en manos del desarrollador y si acaso realmente proviene del desarrollador la aplicación que estamos instalando. El desarrollador necesita firmar digitalmente el propio código y enviar ese código firmado digitalmente a los usuarios finales para que cuando instalen la aplicación el SO comprobará la firma y si falla en la validación de esa firma digital aparecerá un aviso informando que algo a cambiado en esa aplicación.
Sandboxing
Otra técnica de seguridad útil para las aplicaciones es la capacidad de aislar la aplicación en un entorno controlado (Sandbox). Lo que significa que cuando la aplicación comienza a ejecutarse, solo tiene acceso a los datos necesarios para que esa aplicación funcione. Al momento de desarrollar una aplicación también lo hacen en un Sandbox para aislar el desarrollo de los demás sistemas
Application security monitoring
Los desarrolladores muchas veces incorporan sistemas de monitorización en las aplicaciones que crean para supervisar el uso y cualquier problema de seguridad. Por ejemplo, ver si alguien está intentando realizar inyección SQL o intentar aprovecharse de alguna vulnerabilidad. Esto genera registros de uso de la aplicación y los desarrolladores usan herramientas para analizar esos registros e intentar encontrar vulnerabilidades.
4.2 Explique las implicaciones de seguridad de una gestión adecuada del hardware, el software y los activos de datos
Acquisition/procurement process
El proceso de compra y servicios de terceros se necesita la firma y aprobación de varias partes de la organizacion. Parte con una solicitud de un usuario final y luego implica un analisis del presupuesto y si ese departamento en particular puede permitirse comprar ese producto, las aprobaciones formales de TI, del departamento de compras y de la alta direccion.
Assignment/accounting
Luego de comprar un bien tangible se debe agregar a un sistema central de seguimientos de activos para administrar todos los activos recibidos por la empresa.
- Ownership; se debe saber quien tiene el control de ese activo y se le asigna la propiedad en el sistema de seguimiento de activos.
- Classification; debemos asignar el tipo de dispositivo como por ejemplo, ordenador portatil, de escritorio, dispositivo movil, o cualquier otro tipo de sistema. Tambien debemos determinar si se trata de hardware (gasto capital) o software (gasto operativo).
Monitoring/asset tracking
- Inventory; el sistema de seguimiento no solo se utiliza cuando compramos el producto, tambien lo usamos durante todo su ciclo de vida para inventariarlo, saber donde se encuentra y proporcionar algun tipo de seguimiento. Tambien es util para el servicio de asistencia tecnica.
- Enumeration; el sistema de seguimiento de activos tambien permite la enumeracion de los dispositivos por lo que podriamos incluir una etiqueta de identificacion del activo que podemos adjuntar fisicamente al dispositivo
Disposal/decommissioning
- Sanitization; debemos eliminar todos los datos de la empresa en el dispositivo cuando necesitemos reutilizarlo y asegurarnos de que nadie pueda recuperarlos en caso de que queramos retirar o regalar el dispositivo. Si se planeamos desechar completamente el dispositivo es necesario borrar todo lo que hay en la unidad de almacenamiento, en cambio si planeamos usar este dispositivo internamente, es posible que solo necesitemos eliminar ciertos archivos que podrian ser confidenciales.
- Destruction; si queremos garantizar que nadie vuelva a ver jamas los datos de ese disco duro quizás debamos destruirlo físicamente. Tambien se podria electromagnetizar para dejar el disco duro inutilizable o derechamente incinerarlo.
- Certification; se contrata a una empresa externa especializada en destruccion de unidades y este tercero nos confirma de que las unidades fueron correctamente eliminadas y nos entrega un certificado conocido como certificado de destruccion
- Data retention; dependiendo de las normas y reglamentos asociados a la empresa podria existir la obligación para proporcionar retención de datos durante una cierta cantidad de años o tiempo determinado
4.3 Explique diversas actividades asociadas con la gestión de vulnerabilidades
Identification methods
- Vulnerability scanning; los análisis de vulnerabilidades se utilizan para determinar si un sistema puede ser susceptible a un tipo de ataque. Este proceso no realiza ningún ataque al sistema operativo ya que no es una prueba de penetración. Un análisis de puerto, es un análisis simple de vulnerabilidades, también con este proceso se pueden identificar sistemas. Es importante realizar estos análisis desde dentro de la red y desde afuera ya que existe la posibilidad de tener un ataque interno. Se deben realizar los informes de análisis de vulnerabilidades para determinar que tipos de vulnerabilidades pueden existir y cuales podrían ser falsos positivos.
- Application security;
- Static code analyzers; los desarrolladores de aplicaciones utilizan un sistema de pruebas de seguridad de aplicaciones estática (SAST) que es un software que revisa el codigo fuente de una aplicación para determinar donde podrian existir vulnerabilidades potenciales de su aplicación como por ejemplo, desbordamiento de buffer, inyección de base de datos o algún otro tipo de vulnerabilidad. Hay cierto tipo de vulnerabilidades que pueden no aparecer en un analizador de codigo estatico, por ejemplo, un SAST no entiende como se han implementado ciertas tecnologías en el codigo, como problemas relacionados con la seguridad de la autenticación o una implementación insegura de la criptografía, por lo que al igual que los escaneos de vulnerabilidades en la red, también tenemos que comprobar los resultados de los analizadores de codigo estático, determinando que parte del analizador de codigo estático es correcta y cuales de las recomendaciones pueden ser falsos positivos.
- Dynamic analysis (fuzzing); El analisis dinamico o fuzzing está diseña para tomar entradas aleatorias e introducirlas en una aplicación para ver cuales podrian ser los resultados. Tambien se le conoce como inyección de fallos, prueba de robustez entre otros. La idea de este análisis es que se busca que la aplicación responda de forma inesperada como por ejemplo provocar fallo en toda la aplicación, generar un error en el servidor o un mensaje de excepción en la pantalla con el fin de saber dónde podríamos querer proporcionar verificación de entrada adicional en el propio codigo de la aplicación.
- Package monitoring; cuando se instale una aplicación en un sistema es importante verficiar el contenido de ese software, por lo que es necesario preguntarse si el paquete que se está instalando es de confianza y si se descargó directamente desde el fabricante o es de un tercero y en caso de ser de un tercero, lo mas probable es que venga con malware o algún otro tipo de vulnerabilidad. En caso de no estar seguro del contenido del paquete, es recomendable cargarlo en un entorno de laboratorio. - Threat feed; es necesario conocer las amenazas que podrían afectar a la organización y tambien a los agentes que podrian provocar esas amenazas (actores de amenazas).
- Open-Source Intelligence (OSINT); Inteligencia de Fuentes Abierta es información que está disponible para cualquiera en internet como foros, o redes sociales donde al recopilarla puedes obtener información útil para algún ataque en particular.
- Proprietary/third-party intelligence; son empresas que recopilan informacion y las proporcionan a cambio de una tarifa. Una ventaja que tienen estas empresas es que recopilan informacion de muchas empresas y si en algun segmento pueden informar de esa amenaza antes de que llegue a mi organizacion. Estas organizaciones supervisan constantemente el panorama de amenazas para comprender cuales podrian ser las nuevas amenazas y pueden ofrecer ideas sobre como protegerte.
- Information-sharing organization; algunas organizaciones recopilan informacion sobre amenazas para poner los datos a disposicion de sus clientes. Estos datos sobre amenazas se recopilan de fuentes publicas o informacion privada que se a hecho publica.
- Dark web; una de las mejores fuentes para obtener informacion detallada sobre amenazas es la Dark Web. La Dark Web es una red superpuesta que utiliza internet para el transporte pero todo el contenido es accesible solo con software especializado. En este lugar se puede encontrar todo tipo de grupos de hackers, la actividad que realiza, herramientas, datos de tarjetas para la venta, cuentas y password de cuentas, etc.
- Penetration testing; el Pestesting es un proceso en el que simulamos un ataque a nuestros propios sistemas. Es muy similar el proceso que seguimos con el escaneo de vulnerabilidades, excepto que en las pruebas de penetracion utilizamos exploits reales para ver si podemos obtener acceso. Muchas organizaciones realizan estas pruebas estandarizadas en intervalos regulares de tiempo, lo que es una buena practica de seguridad y en ocasiones regulatorio según el tipo de negocio. Antes de realizar la primera prueba de penetración lo primero que hay que hacer es enlistar las reglas de participación, que es una lista formal de normas que se redactan para que todos comprendan el alcance y propósito de esta prueba. Por ejemplo, establecer el horario en que se realizará el pentester, establecer el tipo de prueba (brecha física, prueba interna o externa) establecer el rango IPs, contactos en caso de querer contactar a alguien de la organización, saber como manejar los datos confidenciales que se pudieran encontrar y establecer que sistemas están dentro del alcance de esta prueba y cuales no se deben tocar. Una vez realizada la prueba de penetración es necesario explotar las vulnerabilidades encontradas y esto podría causar que el sistema o servicio falle, es por esto que debemos documentar todas las reglas para no poner en peligro ningún sistema que pueda considerarse critico. El proceso de una prueba de penetración es primero encontrar un exploit que nos permita aprovechar una vulnerabilidad conocida y obtener acceso a un sistema, una vez con acceso tenemos que utilizar ese sistema como punto de partida para movernos lateralmente de un dispositivo a otro, luego tenemos que asegurarnos de obtener persistencia para poder volver a acceder en caso de que instalen un parche de seguridad con la vulnerabilidad encontrada, y para eso se crea una puerta trasera, crear una cuenta en el sistema o cambiar contraseñas predeterminadas de una cuenta existente, en caso de estar fuera de la red podríamos utilizar el primer acceso interno como pivot (punto de partida) para poder acceder a otros sistemas que están dentro de la red y esto se realiza configurando un sistema como un repetidos o un proxy.
- Responsible disclosure program; en las listas de CVE o de cualquier lista de vulnerabilidades hay un flujo constante de vulnerabilidades actualizadas que se hacen publicas, pero antes de que esa vulnerabilidad se hiciera publica se realizó un gran trabajo antes de esa fecha para asegurar que el software pudiera ser corregido y quizás lanzar un parche para esa vulnerabilidad. Para que esto se lleve a cabo, un investigador tuvo que identificar esa vulnerabilidad y luego mostrarla al desarrollador de software o al fabricante y a partir de ese momento el fabricante deberá actualizar su codigo, probarlo y luego publicar una versión actualizada de ese software sin la vulnerabilidad. Pueden pasar semanas o incluso meses en que un ivestigador identifica una vulnerabilidad y el momento en que está disponible un parche para esa vulnerabilidad. Esa información solo se hace publica y se incluye en una lista CVE después de que se publique el parche.
- Bug bounty programs; este proceso suele fomentarse mediante el uso de programas de recompensas por errores. El bug bounty son programas de recompensas por detección de errores con incentivos para quien encuentre una vulnerabilidad en este software.
Analysis
- Confirmation;
- False positive; es informacion que recibimos pero que tenemos que descartar porque simplemente no es correcta, nos referimos a esta informacion falsa como falso positivo, por ejemplo, nos dan informacion que esta vulnerabilidad en particular existe en el sistema operativo pero luego de analizarla nos damos cuenta que en realidad esta vulnerabilidad no existe en el sistema operativo.
- False negative; un falso negativo es mucho peor que un falso positivo ya que significa que la vulnerabilidad si existe en el sistema operativo pero el software de escaneo no la detectó, lo que significa que en el informe de vulnerabilidades conocidas no verá esa vulnerabilidad listada en ninguna parte, por lo que si un atacante llega a ese sistema podria explotar esa vulnerabilidad de la que ni siquiera teníamos conocimiento. Siempre es recomendable actualizar las firma de los escaneos de vulnerabilidades para minimizar falsos positivos o falsos negativos.
- Prioritizing vulnerabilities; esta categorizacion de la gravedad es importante por que es probable que las vulnerabilidades criticas deban abordarse primero y las vulnerabilidades de baja gravedad e informativas pueden ser lo ultimo en abordarse. Existen varias listas de vulnerabilidades disponibles publicamente que ya han establecido estas prioridades permitiendo ordenarlas de la mas critica a la mas baja gravedad.
- Common Vulnerability Scoring System (CVSS); el Sistema Comun de Puntuacion de Vulnerabilidades es una lista de vulnerabilidades que está sincronizada con la lista principal de CVE y a cada vulnerabilidad se le asigna una puntuacion entre 0 y 10 donde 10 es la mas critica.
- Common Vulnerability Enumeration (CVE); son listas de vulnerabilidades que están en linea y la mayoria de los escaneres de vulnerabilidades especifican qué CVE está asociado con esa vulnerabilidad.
- Vulnerability classification; un escaner que vulnerabilidad identificará cualquier vulnerabilidad que encuentre y luego proporcionará informacion adicional sobre como se asocia esa vulnerabilidad con su gravedad, por lo que se debe asegurar el conjunto de firmas mas recientes. Los escaneos de vulnerabilidades pueden buscar diferentes tipos de vulnerabilidades como por ejemplo de aplicaciones de escritorios o de mobiles, aplicaciones web o dentro de equipos de red como firewall, router, entre otros.
- Exposure factor; una forma de entender que tan riesgoso podria ser que esa vulnerabilidad exista en esos sistemas es cuantificar mediante un factor de exposición y generalmente se representa como un porcentaje. Por ejemplo, si una vulnerabilidad pudiera hacer que el servicio no esté disponible la mitad del tiempo, podemos especificar que es un factor de exposición del 50%. O si sabemos que esta vulnerabilidad no tiene parche y está disponible en los servidores web publicos y si alguien la explota podria deshabilitar completamente el servicio por lo que podriamos considerar un factor de exposición del 100%. La puntuaciones CVSS y sus propios factores de exposicion pueden ayudar a comprender donde priorizar las correcciones para las vulnerabilidades especificas.
- Environmental variables; otro aspecto a tener en cuenta al planificar la aplicacion de parches es comprender el entorno. Por lo que se tiene que analizar si la vulnerabilidad podria existir en una nube publica, en un laboratorio de pruebas, o en un server interno por lo que se gestionaria la aplicacion de parches diferentes para cada entorno. Por lo general se toma en cuenta la cantidad de usuarios que utiliza el servicio, considerar si esa aplicacion es clave o critica para la organizacion y si genera ingresos.
- Industry/organizational impact; algunas organizaciones son mucho mas sensibles a cualquier tipo de interrupción que otras, por lo que alguna vulnerabilidad podria tener un impacto distinto en diferentes organizaciones.
- Risk tolerance; uno de los desafios de aplicar parches de seguridad, es que no se pueden aplicar todos al mismo tiempo, por lo que debemos establecer algun tipo de prioridad sobre que parche se instalará primero. El proceso para determinar que dispositivo puede ser mas importante que otro puede depender del riesgo que suponga la existencia de esa vulnerabilidad en el dispositivo. Nos referimos a esta priorización como tolerancia al riesgo, que describe cuanto riesgo está dispuesta a aceptar una organización al mantener sin parchear esa vulnerabilidad. Como no podemos implementar el parche de seguridad hasta saber que funcionará correctamente debemos realizar muchas pruebas, por lo que en este periodo de tiempo seguimos siendo vulnerables y por eso la organización debe decidir cuantas pruebas deben realizarse para implementarse. En caso de que una vulnerabilidad afecte a muchos sistemas y es una vulnerabilidad relativamente facil de explotar es posible que tengamos una tolerancia muy baja y queramos acelerar el proceso de pruebas para poder parchear esos sistemas lo antes posible.
Vulnerability response and remediation
- Patching; en la gran mayoria de los casos se puede mitigar fácilmente una vulnerabilidad instalando un parche de seguridad. Estos parches muchas veces se proporcionan segun una programacion estandar semanal o mensual, pero en caso de que la vulnerabilidad es realmente grave o es un Zero Day con exploits activos es posible que reciba un parche no programado.
- Insurance; otra forma de mitigar estas vulnerabilidades es trasladar el riesgo de su entorno a una poliza de seguro de ciberseguridad. Estas polizas pueden cubrir cualquier perdida de ingresos después de ocurrir un evento. La organizacion tambien podria perder dinero debido a intentos de phishing, ransomware o si alguien presenta una demanda dependiendo de los resultados del ataque por lo que tambien podria entrar la poliza de seguro para estos casos. Algunas cosas que no podrian estar cubiertas con la poliza son los actos intencionados o transferencia de fondos por parte de alguien.
- Segmentation; otra forma de mitigar cualquier tipo de ataque seria limitar el alcance de lo que ese ataque podria provocar mediante la segmentacion. Separar los dispositivos en sus propias redes o VLAN es una forma comun de proporcionar esta segmentación. Esto puede no impidir que un atacante entre a un sistema pero puede impedir que acceda al resto de la red que está afuera de la segmentación. Los NGFWs son buenos monitoreando los flujos de trafico entre estos diferentes segmentos, ya que puede identificar la aplicacion que se está utilizando para la comunicacion entre dichos segmentos.
- Compensating controls; en caso de no poder aplicar un parche de seguridad debido a que por ejemplo este parche cause problemas con otro software o ese parche no se puede instalar en ese momento y no cuenta con un firewall necesitaremos algun control compensatorio como por ejemplo, deshabilitar el servicio que presenta la vulnerabilidad, instalar un firewall perimetral y establecer politicas que impidan que cualquier persona externa acceda a la aplicacion o servicio interno, o tambien la instalacion de un Firewall basado en software instalado en el sistema vulnerable.
- Exception and Exemptions; hay ocaciones que no se pueden instalar parches de seguridad por lo que se decide con un comité de seguridad o un comité de control de cambios si se realiza una exencion o una excepcion ya que no todas las vulnerabilidades son iguales, por ejemplo, existen algunas vulnerabilidades que solo se pueden explotar si te encuentras localmente en ese dispositivo, por lo que si un servidor está dentro de un centro de datos, seria muy poco probable que un atacante consiguiera acceso al centro de datos, por lo que en estos casos el comite podria decidir que no actualizar ese sistema es un riesgo de seguridad razonable.
Validation of remediation
Una vez identificada una vulnerabilidad significativa y se encontró que es una vulnerabilidad que se debe parchear rapidamente y luego se implementa esa actualizacion en todos los sistemas, se debe preguntar ¿Realmente el parche eliminó la vulnerabilidad?.
- Rescanning; una buena practica despues de implementar uno de estos parches es realizar un analisis de vulnerabilidades donde podria confirmar que el parche se ha implementado correctamente y podria encontrar sistemas que necesitan el parche y que tal vez no se conocia.
- Audit; es una buena practica realizar una auditoria en los sistemas para verificar que el parche se instaló correctamente.
- Verification; normalmente el tipo de verificacion se puede realizar a traves del sistema de parches que esté utilizando o puede requerir que alguien inicie sesion en el sistema y confirmar que el parche está instalado y funcionando.
Reporting
en organizaciones grandes es posible que se necesite algun tipo de sistema de informes que indique sobre qué parches se han implementados y cuales son los resultados de dichas implementaciones como por ejemplo, identificar el numero de vulnerabilidades que se han identificado, comprobar que sistemas se han parcheado y cuales no, mostrar notificaciones de nuevas amenazas y saber que parches tuvieron un error, cuales tienen excepciones y exenciones
4.4 Explica los conceptos y herramientas de alerta y monitoreo de seguridad
Monitoring computing resources####
- Systems; algunos puntos de supervision serian nuestros recursos informaticos como sistemas donde hay autenticaciones, las personas que inician sesion y se quiere ver desde donde inician la sesion, monitorizar servicios que se ejecutan en los dispositivos incluyendo el tipo y la cantidad de actividad, comprobar si se ha realizado alguna copia de seguridad y que versiones de software pueden estar instaladas lo que podria ayudar a determinar si un dispositivo necesita ser actualizado.
- Applications; tambien queremos supervisar nuestras aplicaciones comprobando su disponibilidad y asegurarnos de que estos sistemas sigan funcionando, supervisar la cantidad de fallos de seguridad que se han identificado gracias a la monitorizacion del volumen de trafico transferido.
- Infrastructure; supervisar la actividad en curso de su infraestructura como por ejemplo sistemas de acceso remoto como VPN para saber cuantos son empleados, proveedores, y cuantos invitados. Los Firewall y los sistemas IDS/IPS tambien pueden ser una muy buena fuente de informacion.
Activities
- Log aggregation; un SIEM es un Gestor de Informacion y Eventos de Seguridad y permite consolidar archivos de registros de muchos dispositivos diferentes como por ejemplo recopilar logs de Firewalls, Switches, Servidores, Routers y cualquier otro elemento de tu infraestructura. Como todos estos registros estan consolidados en una sola central, es muy sencillo crear informes, comparar y correlacionar datos.
- Scanning; muchas organizaciones cuentan con software y sistemas que pueden escanear constantemente todos los dispositivos de la red e informar sobre metricas relevantes de seguridad. Por ejemplo, chequear que tipo de S.O. tiene un dispositivo y que versiones estan instaladas, que aplicaciones tiene instaladas, tipos de version de drivers, y obtener un informe de posibles anomalias que se hayan identificado y registrado en los archivos de registro de esos dispositivos.
- Reporting; son informes que podrian contener informacion detallada sobre el estado de los sistemas de la red. Los informes practicos o procesables podrian ser un informe que muestre cuantos dispositivos estan actualizados o cumplen con estos parches de seguridad para vulnerabilidades, o establecer que dispositivos no cumplen con la normativa y luego elaborar las acciones necesarias para actualizarlos.
- Archiving; en algunas organizaciones es posible que la ley exija recopilar datos durante un periodo de tiempo determinado.
- Alerting; seria util poder recibir algun tipo de notificacion en el instante en que nuestro sistema detecte algo inusual, como por ejemplo, una alerta al aumentar los errores de autenticacion como lo seria un ataque de pulverizacion (spring) o algun otro tipo de ataque de fuerza bruta.
- Alert response and remediation/validation;
- Quarantine; una vez que se genere una alarma, puede ser importante reaccionar ante ella y una de las reacciones mas comunes es aislar ese sistema poniendolo en cuarentena para evitar que un atacante tenga acceso al sistema.
- Alert tuning; se debe asegurar que todas las alertas sean precisas con el fin de no generar una sobrecarga de alertas provocando falsos positivos o falsos negativos. Por lo general se necesita algo de tiempo para ajustar estas alertas.
Tools
- Security Content Automation Protocol (SCAP); un desafio que puede tener una empresa es que un NGFW un IPS un escáner de vulnerabilidades entre otras herramientas podrian identificar la misma vulnerabilidad pero utilizando terminos, titulos y descripciones diferentes para la misma vulnerabilidad. Para este problema la industria creo el Protocolo de Automatizacion de Contenido de Seguridad (SCAP) por en NIST. SCAP permite consolidar las vulnerabilidades en un lenguaje unico donde todos los dispositivos lo comprenderán, lo que significa que las herramientas como un NGFW, IPS y escáner de vulnerabilidades pueden trabajar juntas y automatizar la deteccion y eliminacion de estas vulnerabilidades.
- Benchmarks; las referencias se pueden obtener de una lista de las mejores practicas para un sistema operativo en particular y configurar todo el S.O. para que sea lo mas seguro posible. Por ejemplo una referencia de un dispositivo movil seria desactivar los screenshots, impedir la llamada de voz cuando el sistema está bloqueado, forzar las copias de seguridad, etc.
- Agents/agentless; uno de los desafíos para mantener seguros a todos los dispositivos son los constantes cambios de los dispositivos encontrando nuevas vulnerabilidades. Lo que significa que cada vez que estos sistemas se conectan a una red o alguien inicia sesión tendemos a escanear el sistema para asegurarnos de que cumpla con las normas. En ocasiones se hace con un agente que se ha instalado en el dispositivo y otros casos podríamos ejecutar una verificación sin agente bajo demanda. Para instalar un agente en un sistema se necesita un programa de configuración y es necesario planificar la instalación del agente antes de realizar la verificación. Una ventaja del sistema basado en agentes es que siempre está activo y en funcionamiento para verificar y asegurarse de que el sistema cumpla con las normas. Una comprobación sin agente se ejecuta sin realizar ningún tipo de instalación formal y generalmente se ejecuta cuando inicia sesión por primera vez o se conecta a algo como un concentrador de VPN, luego se ejecutará en la memoria del sistema y verificará que cumpla con las normas para luego eliminarse automáticamente del sistema.
- Security Information and Event Management (SIEM); un Gestor de Eventos e Información de Seguridad se utiliza comúnmente para consolidar archivos de registros en una base de datos central, luego con esos archivos de registros creamos numerosos informes para monitorear como está funcionando la seguridad en la red. Estos logs al quedar guardados pueden ser utilizados para crear informes forenses.
- Antivirus y antimalware; es otra herramienta de seguridad que se incluye con muchos SO y se utilizan para identificar software maliciosos como Troyanos, gusanos, virus, entre otros.
- Data Loss Prevention (DLP); para evitar que se transfieran datos confidenciales debes utilizar un programa llamado Prevención de Datos Perdidos, también se usa para buscar y bloquear cualquier tipo de datos que no deseamos que se ejecuten en la red.
- Simple Network Management Protocol (SNMP);Probablemente tienes un software de monitoreo integrado en el sistema que recopila y proporciona información mediante SNMP o Protocolo Simple de Administracion de Redes. Dependiendo del dispositivo hay una base de datos especifica de información que se recopila en el sistema. Nos referimos a esta base de datos como Base de Informacion de Gestion (MIB). Dentro del MIB hay una serie de métricas que están siendo monitoreadas y en lugar de deletrear el nombre individual de cada métrica se utiliza Identificadores de Objeto (OIDs) que son un grupo de números. Al observar una captura de paquetes de red se pueden ver datos SNMP por el puerto UDP161. Por lo tanto siempre la estación de red estará preguntando al dispositivo como router, firewall, switch, server, Workstation cuanta información se ha transferido en bytes en una interfaz particular por lo que el dispositivo responderá con el valor que corresponde y se realizará la misma operación cada ciertos minutos. Con esta información se pueden crear gráficos y diagramas entre un periodo de tiempo y otro.
- SNMP Traps; este proceso de recopilar información utilizado por SNMP requiere que la estación de administración sondee el dispositivo en intervalos regulares, pero en caso de que no se envien los datos en tiempos regulares se activaria la trampa SNMP, es decir cuando el dispositivo remoto que ejecuta SNMP no puede enviar el sondeo se activará la trampa SNMP mediante el protocolo UDP 162 enviando una alarma o alerta. Por ejemplo, podriamos estar monitoreando errores de CRC en un servidor y configuraremos el agente SNMP en ese servidor para esperar hasta que la cantidad de errores de CRC aumente a 5 y en caso de llegar a 5 envíe una trampa de regreso a la estacion de administracion y una vez recibiendo esta trampa puede enviar alertas, alarmas, mensajes de texto y correos electronicos entre otros.
- NetFlow; SNMP se centra en recopilar metricas de nivel inferior como el estado general del hardware como el uso de CPU, memoria, temperatura, etc. En cambio NetFlow se centra en un analisis detallado del trafico de red identificando quien lo usa, para qué y donde proviene observando estadisticas relacionadas con el uso de aplicaciones. NetFlow suele funcionar primero con una sonda para compilar esta informacion pudiendo estar esta sonda integrada en el software que vienen incluido con un router o switch, o puede incluirse como una sonda externa separada pudiendo conectarse a la red con un puerto de monitoreo desde el switch como un analizar de puerto conmutado (SPAN), o puede haber una toma fisica en la red que proporcione a la sonda NetFlow una copia de todos los flujos de trafico de la red, luego estas sondan recopilan la informacion y envian una copia a un recopilador NetFlow que luego puede usarse para crear informes.
- Vulnerability scanners (nessus o Nmap); tambien podemos recopilar una gran cantidad de informacion sobre nuestra postura de seguridad utilizando un escaner de vulnerabilidad que está diseñado para ser minimamente invasivo por lo que no realizará ataque a ningun sistema pero recopilará detalles sobre si un sistema podria potencialmente tener una vulnerabilidad. Tambien proporcionan un escaneo de puertos, una lista de direcciones IP o rango. Mayormente realizaremos estos escaneos de red desde adentro de la red pero es importante tambien hacerlo desde afuera para ver que podria encontrar un atacante desde afuera. Un escaner de vulnerabilidades recopila mucha informacion y no todo es preciso, por lo que es útil realizar un analisis de vulnerabilidad para verificar la información.
4.5 Dado un escenario, modifica las capacidades empresariales para mejorar la seguridad
Firewall
Un Firewall basado en red es un dispositivo que se encuentra en línea en la red y toma decisiones sobre si se debe permitir o denegar el trafico observando los números de puertos o si el firewall es un NGFW observa la aplicación utilizada. Tambien presta el servicio de puntos finales VPN o concentradores VPN donde pueden haber conexiones punto a punto entre diferentes sitios o usarse como VPN de acceso remoto. Tambien pueden utilizarse como un router ofreciendo servicios de enrutamiento como NAT o enrutamiento dinamico en el punto de entrada y salida de la red. Next-Generation Firewalls (NGFW); el firewall de siguiente generación puede analizar el trafico que fluye y reconocer la aplicación que se está utilizando para tomar decisiones sobre si esa aplicación puede pasar a través del firewall o no.
- Ports and protocols; los firewalls tradicionales, no tienen la capacidad de comprender qué aplicación estaba atravesando la red ya que solo sabían el numero de puerto que se comunicaba del punto A al puento B. Los NGFW brindan mucha mas flexibilidad para comprender la aplicación exacta y con solo indicarle permitir o denegar el trafico de un servidor web y los firewall tradicionales se tendría que especificar el puerto 80 o 443 para https.
- Firewall rules; la mayoría de las reglas de firewall comienzan en la parte superior y bajaran evaluando cada regla individualmente hasta que coinicida con una regla que figura en esa base de reglas, por lo que en general se ponen las reglas mas especificas en la parte superior para que sean reconocidas rápidamente y también todos los firewalls incluirán una denegación implícita.
- Access Control Lists (ACLs); es otra forma de describir una base de reglas o lista de políticas en un firewall donde se detalla primero “Numero de regla”, “IP remota”, “Puerto remoto”, “Numero de Puerto local”, “Protocolo (TCP o UDP)”, “Accion (Denegar o Permitir)”.
- Screened subnets; una subred filtrada generalmente contiene servicios y dispositivos a los que las personas de internet deben acceder y en esa red no pondremos dispositivos ni datos confidenciales con el fin de impedir que cualquier persona de internet acceda a la red interna pero si pueda acceder a los servicios de la subred filtrada.
IDS/IPS
- IPS Rules; también se tienen reglas para los IPS, monitorea el trafico en tiempo real y utiliza firmas cargadas en el IPS para poder reconocer cualquier tipo de software malicioso.
- Signature; muchas de las reglas integradas en un IPS utilizan una firma donde si el trafico coincide con la firma el IPS puede reaccionar y tomar decisiones sobre si ese trafico se debe permitir o denegar. Tambien un IPS puede configurarse para reconocer por ejemplo una inyección de base de datos y si está la reconoce el IPS bloqueará ese trafico.
Web Filter
Los filtros webs están diseñados para controlar qué datos salen y cuales entran filtrando el contenido para restringir qué tipo de información se ve en el navegador de los usuarios. Algunos filtros de contenido están diseñados para bloquear el acceso a sitios conocidos como malos.
- Universal Resource Locator (URL) scanning; un tipo de filtro de contenido es aquel que filtra según un Localizador Uniforme de Recursos o URL. Si desea que los usuarios puedan acceder a un sitio web en particular puede agregar esa URL a una lista de permitidos o si quiere bloquearlo puede agregar la URL a una lista de bloqueados. Muchas de las tecnologías de filtrado agrupan las URLs según el tipo de categoría de la pagina web. En la actualidad este tipo de filtrado viene incorporado en en NGFW.
- Agent-based; los filtros de contenido basado en agentes se instalan en los escritorios y dispositivos de los usuarios gestionados desde una consola central, por lo que no tenemos que estar detrás de un firewall ya que el dispositivo tiene instalado el agente y en cualquier red o lugar aplicará el filtro.
- Proxies; en lugar de gestionar el control del contenido desde un filtro URL o un firewall de ultima generación, algunas empresas utilizan servidores proxy. Un proxy es un dispositivo que se encuentra entre los usuarios y una red externa y le permite controlar el flujo de trafico a través de ese proxy. Con un firewall tradicional, los usuarios se comunican directamente con los sitios web pero un proxy se sienta en medio de la conversación y hace esas solicitudes en nombre del usuario y en caso de ser una URL permitida reenviará la respuesta de la pagina web al usuario final. También podríamos hacer que el proxy actúe como caché guardando localmente la información de la pagina para que si otra persona visita el mismo sitio el proxy responda con la información que está en el caché. El proxy también provee control de acceso, lo que significa que limita qué dispositivos pueden comunicarse a internet y se puede gestionar por usuario y contraseña o basarse en una direccion IP. Con algunos proxies tenemos que indicarles a nuestras aplicaciones que utilice el proxy para comunicarse, en lugar de comunicarse directamente con un servidor, esto se llama proxy explicito porque estamos configurando explícitamente ese proxy en la configuración de la aplicación. Tambien hay proxies que no requieren esta configuracion (explicito) y pueden funcionar en el cliente sin necesidad de configurar nada por lo que el cliente final no se da cuenta que está usando un proxy, se llama a este proxy transparente.
- Block rules; existen reglas de bloqueo basados en URL que están diseñados para bloquear en función de un nombre de dominio completo, también en función a una categoría como por ejemplo “Adult”.
- Reputation; algunos filtros de contenido y filtros de URL tienen en cuenta mas que solo un nombre de dominio completo, podrian evaluar la reputacion del sitio y permitirlo o bloquearlo segun el riesgo percibido de los datos en ese sitio. Esta reputacion puede estar clasificado en; riesgo bajo, riesgo medio, sospechoso o riesgo alto.
DNS filtering
Otra manera de proporcionar filtrado de contenido sin un firewall de ultima generacion, un proxy o un filtro de URL. Esta es utilizando un filtrado DNS, ya que hay muchos nombres de dominio que se sabe que tienen contenido cuestionable o simplemente pueden contener codigo malicioso por lo que podriamos configurar el DNS para no proporcionar al usuario la direccion IP de ese sitio. Se pueden utilizar listas comerciales y listas disponibles públicamente para usar el filtrado de DNS.
Operating system security
- Active Directory; es una base de datos que contiene todos los diferentes componentes de la red, las cuentas de usuario, lista de los recursos compartidos de archivos e impresoras, grupos de seguridad y cualquier otra cosa que conforma la red y de aca podemos gestionar toda la autenticacion desde este recurso central
- Group Policy; podemos superponer un grupo de politicas de seguridad en esta lista de computadoras y usuarios que están almacenados en active directory llamado Politica de Grupo. Esta politica de grupo nos permite establecer diferentes configuraciones o permisos para cada usuario individual o un dispositivo. Generalmente esto se ejecuta desde una consola central conocida como Editor de administracion de politicas de grupo y podriamos configurar scripts de inicio de sesion cuando un usuario se conecta a la red, configuraciones de red como QoS y parametros de seguridad. Esta combinacion de Active Directory y Politicas de Grupo nos permite crear un mecanismo de control integral para todo lo que está en la red.
- SELinux; el SO Linux por defecto funciona como un dispositivo de Control de Acceso Discrecional (DAC), lo que significa que el usuario tiene su propia discreción para poder asignar derechos y permisos a diferentes recursos en el sistema operativo Linux, por lo que para entornos mas seguros un control de acceso discrecional no es apropiado, por lo que utilizarían un Control de Acceso Obligatorio (MAC) donde todos esos derechos y permisos son asignados por un administrador central. Para proporcionar este control de acceso obligatorio se instalar una serie de parches que habiliten Security-Enhancerd Linux o SELinux y esto permite que el administrador del sistema aproveche el minimo privilegio y se asocian los derechos y permisos al usuario.
Implementation of secure protocols
- Protocol selection; el objetivo siempre debe ser utilizar un protocolo seguro que utilice encriptación para proteger todos los datos enviados a través de la red. Por ejemplo, para una aplicacion de consola remota utilizar SSH en vez de Telnet, https en lugar de http, para el cliente de correo utilizar IMAPS en vez de IMAP y en vez de transferir archivos por FTP utilizar SFTP.
- Port selection; a veces es posible saber si un protocolo es seguro o no segun el numero de puerto que utiliza, algunos protocolos utilizarán un numero de puerto como la version insegura y un numero de puerto diferente para la versión segura y cifrada. Por ejemplo, para HTTP el puerto 80 y para HTTPS el puerto 443. Sin embargo el hecho de utilizar un determinado puerto este en uso no garantiza que ese trafico utilice una version cifrada o un protocolo seguro.
- Transport method; adicional al cifrado del protocolo, se recomienda utilizar un metodo para cifrar todo el trafico enviado, por ejemplo, en vez de utilizar 802.11 con un punto de acceso abierto lo que significaría que ninguno de los tráficos se cifrará a medida que pase por la red inalambrica, pero si configura en WPA3 o un protocolo similar en el Access Point, todos los datos enviados a través de esta red inalámbrica estarán cifrados. Tambien un metodo de transporte seguro es utilizar un cifrado a nivel de red utilizando una VPN, creando un tunel cifrado entre el dispositivo y el concentrador VPN.
Email security
Existen controles de seguridad que podemos agregar a nuestros servidores DNS para que nos permita confirmar si una dirección de correo electrónico realmente fue enviada desde un servidor legitimo.
- Mail Gateway; el mail gateway es el dispositivo que toma la decisión de si un correo electrónico es legitimo o si debe ir a la carpeta de spam.
- Sender Policy Framework (SPF); el marco de política de remitente (SPF) se debe agregar al servidor DNS ya que este protocolo define qué servidores de correo electrónico están autorizados a enviar correo en nuestro nombre. Este registro se agrega a nuestro DNS como un registro de texto o TXT y así cuando yo envié un correo a un tercero, al momento de recibirlo este destinatario verificará mi servidor DNS e intentará encontrar todos los servidores que tienen permiso para enviar correo en mi nombre.
- Domain Keys Identified Mail (DKIM); se puede proporcionar una verificacion adicional a mis correos salientes mediante firmas digitales configurando el servidor de correo para que firme digitalmente todos los correos que se envían a un tercero y esto utiliza una clave que se puede validar desde un DKIM o Registro de Correo identificado por DomainKeys. Esta firma digital se añade al proceso de transporte entre servidores de correos por lo que para verlo se tiene que mirar los encabezados del correo electrónico.
- Domain-based Message Authentication, Reporting, and Conformance (DMARC); Podemos especificar que hacer con los correos que no se validó de forma correcta el SPF y DKIM agregando un registro DMARC a nuestro DNS. DMARC significa Autenticación, informes y conformidad de mensajes basados en dominio siendo una extensión de SPF y DKIM y se agrega en un registro de texto DNS que se agrega para definir qué hacer con los mensajes, pudiendo tener como opción enviar los mensajes a SPAM, recibir de igual forma los mensajes o rechazar los correos
File Integrity Monitoring (FIM)
Generalmente en las aplicaciones hay archivos que cambian y otros que rara vez cambian salvo alguna actualización, por lo que es recomendable aplicar monitoreo y alertas en caso de que estos archivos cambien y se puede hacer con un tipo de software llamado File Integrity Monitoring (FIM) y en Windows se encuentra el SFC (System File Checker) escaneando todos los archivos críticos y verificando que ninguno de esos archivos cambió o modificó y en caso de modificar SFC reemplazará esos archivos con una buena versión. En Linux tenemos Tripwire.
DLP (Data Loss Prevention)
La herramienta de Prevencion de Perdida de Datos es un sistema que pueden buscar datos confidenciales que se envían a través de la red y bloquear este tráfico en tiempo real, entonces si alguien transmite números de por ejemplo seguro social, información medica o cualquier otra cosa que pueda considerarse confidencial podemos bloquearlo utilizando DLP en tiempo real. A menudo nos referimos a estas soluciones DLP en la computadora como algo que monitorea los datos en uso, lo que significa que están en la memoria activa, y en caso de estar conectada a la red monitoreando paquetes en tiempo real denominamos a este monitoreo datos en movimiento y si se necesita monitorear archivos que están almacenados en un servidor se llama monitorear los datos en reposo. DLP también puede bloquear los puertos USB para mayor seguridad. Cloud-based DLP es muy similar a DLP que se ejecuta en una estación de trabajo o un dispositivo basado en la red ya que se ejecuta como un dispositivo basado en la nube y supervisa todo el trafico que entra y sale de la aplicación basada en la nube. También puede bloquear los correos electrónicos que pueden enviar información confidencial
Network Access Control (NAC)####
El Control de Acceso a la Red es un proceso que restringe el acceso a una red privada a usuarios y dispositivos no autorizados o que no cumplen las politicas de seguridad. NAC verifica la identidad de los usuarios y el estado de cumplimiento de los dispositivos como por ejemplo si tienen antivirus actualizado, parches y actualizaciones al dia, etc.
Endpoint Detection and Response (EDR)/Extended Detection and Response (XDR)
EDR es una forma moderna de monitorear los puntos finales ya que está diseñado para tomar la idea de las firmas y extender su visibilidad a cosas como el análisis del comportamiento o el aprendizaje automático, poder monitorear los procesos que se ejecutan en el sistema y correlacionar todos esto junto para determinar si podría existir una amenaza. Generalmente se ejecuta como un agente en el punto final igual a un agente antivirus o antimalware. Con EDR podemos determinar por qué ese virus entró en el sistema y luego trabajar hacia atras para encontrar una forma de eliminarlo y evitar que infecte otros sistemas. Deteccion y Respuesta Extendida (XDR) proporciona inteligencia adicional y un mayor alcance de entrada de datos para descubrir cualquier software malicioso. Es decir podemos detectar cosas que con EDR podrian haber pasado inadvertidas y cualquier cosa que pudiera haber resultado como un falso positivo ahora podria categorizarse correctamente
User behavior analytics
El analisis del comportamiento del usuario es una fuente de datos que se utiliza para XDR para interpretar la actividad del usuario y así crear una linea base. XDR sabe qué usuarios estarian comunmente en esta red, a qué dispositivos se conectarian, el tipo de trafico de red que transfieren y los repositorios de datos a los que acceden estos usuarios
4.6 Dado un escenario, implementar y mantener la gestion de identidad y acceso
Identity and Access Management (IAM)
Necesitamos dar los permisos adecuados a las personas adecuadas en los momentos adecuados para brindarles el acceso que necesitan. A esto lo llamamos Gestion de Identidad y Accesso (IAM). IAM comienza con el proceso cuando un usuario necesita acceso (recien contratado) y finaliza con la eliminacion de ese acceso al usuario (desvinculado). IAM es responsable de determinar el control de acceso al momento de ingresar en la empresa por lo que es posible que tenga una lista de prioridades como acceso al correo electronico, acceso a una aplicacion principal y acceso a internet. Tambien requiere que el usuario se identifique de alguna manera con algun nombre de usuario y password y por ultimo necesitamos registrar y monitorear todo el acceso a estos datos cumpliendo con la triple AAA (autenticacion, autorizacion y account)
Provisioning/de-provisioning user accounts
Este proceso de IAM comienza con la creacion de una cuenta de usuario y finaliza cuando la cuenta se desactiva, por lo que suele ocurrir durante la incorporacion y la salida del personal o cambiar cuando alguien asciende o se traslada a otra parte de la empresa. Este proceso de aprovisionamiento de un usuario y desaprovisionamiento de la cuenta de usuario es el nucleo de IAM garantizando que se asignen los permisos correctos segun los detalles como el nombre de usuario, atributos, permisos de grupos y otros permisos.
Permission assignments
Uno de los objetivos principales de IAM es garantizar que los permisos asignados a un usuario sean los necesarios para que ese usuario haga su trabajo y que ningun permiso se extienda mas allá de ese objetivo particular. Cualquier documento que crea el usuario es privado para ese usuario, por lo que si otra persona inicia sesión en ese dispositivo no debería acceder a esos archivos. Tambien limitariamos el acceso del usuario al sistema operativo principal para evitar que el usuario realice cambios en el SO evitando tambien que algun malware realicen cambios en el SO
Identity proofing
Otra parte importante de IAM es la verificacion de identidad del usuario con un proceso formal durante la creacion de la cuenta para verificar que un usuario realmente es quien dice ser. Este proceso se denomina resolucion y es un paso importante para garantizar que no estemos asignando derechos y permisos a alguien que no debería estar en nuestra red. La verificacion de identidad se podria realizar mediante la cedula de identidad, pasaporte, etc.
Single sign-on (SSO)
El inicio de sesión único (SSO) es cuando se inicia sesión una vez en la red y se obtiene el acceso a todos los recursos que pueda necesitar, independiente de donde se encuentren esos recursos. Sin SSO se tendrá que proporcionar user y password cada vez que por ejemplo se conecte una impresora o acceder a algún archivo compartido, en cambio con SSO como ya se inició sesión no es necesario volver a digitar sus credenciales usualmente por 24 horas.
- LDAP (Lightweight Directory Access Protocol); el Protocolo Ligero de Acceso a Directorios (LDAP) es un protocolo para acceder a grandes directorios de datos en una red y el estándar es la especificación X.500.
- SAML (Security Assertion Markup Language); es otro protocol estandar para autenticación y autorización. Este Lenguaje de Marcadao de Afirmacion de Seguridad permite la autenticación de un usuario en una base de datos de terceros, haciendo que en lugar de mantener su propia base de datos de usuarios, puede simplemente utilizar una que ya se haya creado en otro lugar. Sin embargo SAML no fue diseñado para dispositivos móviles. Un proceso SAML básico involucra tres dispositivos diferentes, el primero es el dispositivo que estoy utilizando (cliente), el segundo dispositivo es el servidor donde queremos obtener recursos y el tercer dispositivo es el servidor que hace el proceso de autenticación y autorización. El proceso inicia cuando el cliente accede al servidor de recursos, luego el servidor recursos envia una solicitud SAML cifrada y la redirecciona al servidor de autorización, el usuario proporciona las credenciales de acceso para acceder al recurso al servidor de autorización, este servidor de autorización verifica las credenciales y aprueba que sean correctas creando un token SAML, el cliente ahora con la copia del token lo presenta al servidor de recursos para obtener el acceso.
- OAtuth (Open Authorization); es un protocol que fue creado para funcionar con nuestros sistemas mas modernos y móviles siendo un marco de autorización y una vez que se autentica, OAuth determina a qué recursos puede tener acceso un usuario. Con este marco se puede dar acceso a usuarios donde quiera que estén y desde cualquier sistema que usen. Dado que OAuth es un marco de autorización aun es necesario que exista algo que proporcione autenticación por lo que a menudo vemos que OpenID se utiliza junto con OAuth para combiar la autenticación con la autorización.
Federation
Puede haber ocasiones en las que desee iniciar sesión en un recurso, pero no quiero crear otra cuenta en ese recurso en particular. En lugar de ello, es posible utilizar la federación, ya que permite el acceso a la red sin utilizar una base de datos de autenticación local, por ejemplo, utilizar la cuenta de Google cuando quiero iniciar sesión en Spotify y así no es necesario crear una cuenta de Spotify.
Interoperability
Cuando una empresa toma la decisión sobre qué tecnologías debería utilizar, debe asegurarse de que todas sean interoperables. Por ejemplo, al implementar un nuevo concentrador VPN observan que las opciones disponibles admite el acceso a un servidor LDAP para autenticación lo que si la empresa tienen un servidor Active Directory o algún otro tipo de servidor LDAP para autenticación es una combinación perfecta entre lo que necesita el concentrador VPN y los recursos que están disponibles actualmente.
Access controls
- Least privilege; una práctica recomendada de seguridad que se puede aplicar a cualquier control de acceso que mencionaremos a continuacion es la del mínimo privilegio y significa que asignaremos derechos y permisos a un usuario lo más mínimo posible para que pueda realizar su función sin darle permisos ni derechos adicionales.
- Mandatory Access Control (MAC); el control de acceso obligatorio generalmente se utiliza en un área de alta seguridad asignando una etiqueta (confidencial, secreto, utrasecreto, etc.) a cada recurso al que alguien puede necesitar acceder. En este tipo de control el administrador del sistema es quien define qué tipo de derechos y permisos puede tener un usuario.
- Discretionary Access Control (DAC); un tipo comun de control de acceso es el Control de Accesso Discrecional. En este modelo, el usuario que crea los datos tienen el control sobre quien puede acceder a ellos y como puede acceder a esa información, pero este nivel de acceso es menos seguro porque depende de cada usuario que establezca los controles de seguridad adecuados.
- Role-based Access Control (RBAC); un modelo de control mas centralizado es el Control de Accesso Basado en Roles. Este control se basa en su función laboral por ejemplo, si eres un “administrador” tienes cierto tipo de derechos, si eres un “gerente” tienes acceso a otros derechos, si eres un “supervisor” tienes derecho a otros permisos. El administrador tiene que crear varios grupos diferentes asignándoles derechos y permisos a cada grupo para luego agregar a los usuarios a cada grupo correspondiente a su función.
- Rule-based Access Control; el Control de Accesso Basado en Reglas tiene una serie de reglas impuestas por el sistema creadas por el administrador siendo esta persona responsable de configurar y asignar todos los permisos. Con este tipo de control primero crearíamos un aregla y luego asociaríamos esa regla con un objeto especifico y así cada usuario que accede a ese objeto se verifica en la base de reglas para ver si alguna de esas reglas podría aplicarse a ese individuo. Por ejemplo, un usuario quiere acceder a unos datos pero se encuentra una regla para esos datos que solo se puede acceder entre las 09 y 17 horas, por lo que si se encuentra fuera de ese rango de horario, la regla bloqueará ese acceso. Este tipo de control de acceso permite a un administrador establecer cualquier tipo de criterio y asociar ese criterio a un objeto especifico.
- Attribute-based Access Control (ABAC); un Estilo mas moderno de control de acceso es el Control de Acceso Basado en Atributos y con este tipo de control hay muchos criterios diferentes para determinar si alguien tendrá acceso a los datos, permitiendo a los administradores crear un conjunto de reglas complejas que determinan si ciertos datos son accesibles o no. Un ejemplo seria, evaluar la dirección IP de la persona junto con la hora del dia, la acción deseada, si está escribiendo o leyendo la información y que relación podría tener con los datos.
- Time-of-day restrictions; un administrador puede permitir o denegar el acceso a un determinado tipo de datos u objeto de recurso según la hora del día ofreciendo al administrador opciones a la hora de configurar el acceso a los datos.
Multifactor Authentication
Algunos factores de autenticación muy comunes son algo que sabes, algo que tienes, algo que eres o algún lugar en el que te encuentras.
Privileged Access management tools
- Just-in-time permissions; en el área de TI, en lugar de usar contraseñas individuales se usan Permisos Justo a Tiempo permitiéndole a un técnico reciba acceso administrativo por un tiempo limitado junto con las credenciales temporales. Con esto se resuelve que un técnico necesite derechos de administrador pero no tienen los derechos normalmente asociados con su inicio de sesión.
- Password vaulting; la bóveda de contraseñas contiene credenciales primarias que permitirían a alguien acceder a un sistema, pero en lugar de entregar esas credenciales la bóveda establecerá controles diferentes para cada usuario individual.
- Ephemeral credentials; estas credenciales solo se asignaran temporalmente lo que significa que nunca se muestran las credenciales principales
4.7 Explica la importancia de la automatizacion y la orquestacion relacionadas con operaciones seguras
Use cases of automation and scripting
- User provisioning; muchas organizaciones automatizaran el proceso de incorporacion y salida de personal
- Guard rails; la automatizacion tambien puede utilizarse para evitar errores en los pagos y esto es llamado guard rails o barandilla y es una verificacion automatizada de la informacion que ingresa a un sistema
- Security groups; se podria monitorear grupos de seguridad si una persona agrega al grupo de administradores para que informe de inmediato
- Ticket creation; se puede crear un correo con una solicitud y convertirlo en un ticket en funcion a lo que contiene la solicitud
- Escalation; se puede escalar de forma automatica algun problema sin intervención humana
- Enabling/disabling services and access; se puede utilizar la automatizacion para habilitar o deshabilitar servicios
- Continuous integration and testing; desarrolladores de aplicaciones pueden usar scripts para proporcionar actualizaciones de codigo y desarrollo constantes
- Integrations and Application Programming Interfaces (APIs); se puede usar la automatizacion para hablar directamente con las interfaces de programacion de aplicaciones (APIs) en dispositivos como Firewalls o Infraestructura en la nube
Benefits
- Efficiency/time saving; la creacion de scripts ahorra mucho tiempo y podremos ejecutar estos scripts cuando los necesitemos
- Enforcing baselines; la automatizacion tambien nos puede ayudar a aplicar normas de seguridad
- Standard infrastructure configurations; se pueden configurar scripts para configuraciones de infraestructura.
- Scaling in a secure manner; al escalar una infraestructura en la nube se puede ampliar la seguridad con todo lo demás para esa aplicacion en la nube
- Employee retention; tambien se puede automatizar un scripts en tareas repetitivas donde el tecnico puede dejarlo correr y él preocuparse de otras tareas
- Reaction time; reacciona muy rapidamente si identifica un problema
- Workforce multiplier; los scripts se pueden ejecutar las 24 horas los 7 dias de la semana y no es necesario que una persona supervise manualmenten el servidor
Other considerations
- Complexity; los scripts pueden ser relativamente complejos y tienen que interactuar con otros dispositivos lo que requiere una gran cantidad de pruebas
- Cost; puede tener un costo alto el desarrollo de un scripts
- Single point of failure; un script puede ser un unico punto de falla por lo que si falla podria haber un problema importante con los dispositivos
- Technical debt; la deuda tecnica es cuando se trata de resolver los sintomas en lugar de resolver el problema raiz y a veces crear un script para ocultar un problema mayor puede aumentar la deuda tecnica
- Ongoing supportability; la compatiblidad continua puede ser que hoy funcione el script de forma correcta pero mas adelante cuando cambie el SO puede presentar problemas
4.8 Explica las actividades apropiadas de respuestas a incidentes
Process
El Instituto Nacional de Estandares y Tecnologia (NIST) tiene el documento SP800-61 que es una guía de manejo de incidentes de seguridad informática guiándonos a través de todo el ciclo de vida del manejo de indicentes, incluida la preparación, la detección y el análisis, la contención, la erradicación, la recuperación y cualquier actividad posterior al incidente
- Preparation; antes de que ocurra un incidente se lleva a cabo una gran cantidad de planificación. Una de las cosas que deben estar disponibles es la lista de métodos de comunicación que es una lista con contactos actualizadas con todas las personas que deben ser informadas cuando ocurre un incidente. Tambien un kit de emergencia donde se tenga todo el hardware y software necesario para abordar cualquier tipo de incidente, contar con imágenes limpias de los SO para una rápida instalación y también debería contar con un conjunto de políticas y procedimientos que todos seguirán durante uno de estos incidentes de seguridad
- Detection; se debe asegurar de contar con las políticas y procedimientos adecuados sobre como buscar estos incidentes y que hacer cuando se encuentre con uno.
- Analysis; el análisis mediante varios registros podrian mostrar instancias en las que se intentó atacar la red proporcionando información sobre donde pueden originarse los ataques, que tipo de ataques pueden optar por utilizar y cuando ocurrió el ataque.
- Isolation and containment; una vez que descubres que se está produciendo un ataque se debe detenerlo lo mas rápidamente posible. Los sistemas como Sandboxes ofrecen una forma de probar si hay un ataque dentro de un entorno aislado.
- Eradication; para erradicar el malware es posible que se necesite eliminarlo o volver a crear una imagen del sistema, deshabilitar las cuentas de usuarios que fueron vulneradas y corregir las vulnerabilidades.
- Recovery; en este paso se podrian restaurar las copias de seguridad con el fin de reemplazar los archivos que pueden haber sido comprometidos.
- Lessons learned; una vez finalizado un ataque se debe reflexionar y entender qué pudo haber ocurrido y como podríamos hacerlo mejor la próxima vez y esto se conversa en una reunión posterior al incidente respondiéndose preguntas como por ejemplo, ¿qué ocurrió exactamente?, ¿funcionó el proceso de planificación?, ¿Qué podríamos hacer de manera diferente la próxima vez?, ¿Pasamos por alto algún indicador que nos pudo haber advertido del ataque?.
Training
Toda la planificación y capacitación que se requiere para la respuesta a incidentes debe llevarse a cabo antes de que ocurra un incidente. La idea es que todos sepan que hacer ante un incidente, por lo que tenemos que entender que ocurre durante la respuesta inicial, cuales son los panes de investigación cuando se identifica un incidente, cual es el proceso para informar sobre el incidente, entre otros.
Testing
Antes de que ocurra un evento de seguridad real, siempre es una buena idea realizar algunas pruebas. Esto dará la oportunidad de evaluar qué tan bien documentados podrían estar sus planes de respuesta.
- Tabletop exercise; el ejercicio de mesa implican que todos se sienten alrededor de una mesa y repasen logisticamente las politicas y los procedimientos para estos eventos de seguridad
- Simulation; una simulacion nos permite realizar un ataque simulado y ver cuales podrian ser los resultados de ese ataque, por ejemplo una prueba de phishing y ver como responde el personal y los sistemas
Root cause analysis
el análisis de causa raíz nos puede dar información sobre procesos y procedimientos que no funcionaron como se esperaba o en los que descuidamos por completo una parte particular de nuestra infraestructura de seguridad. Esto se podría hacer recolectando evidencia para poder reconstruir y comprender como la persona entró en la red
Threat hunting
el proceso de caza de amenazas es que nosotros encontremos primero la vulnerabilidad con el fin de poder remediarla antes de que un verdadero atacante lo haga. Esto lo realizariamos con nuevas reglas de firewall, rastreando los tipos de vulnerabilidades que se anunciaron los ultimos dias, revisando los sistemas que se encuentren con los ultimos parches, etc.
Digital forensics
los detalles sobre como recopilar los datos y almacenar la informacion de algun evento en particular se pueden encontrar en en el RFC 3227 y contiene las pautas para la recopilacion y el archivo de evidencia
- Legal hold; la retencion legal es un tipo de solicitud de adquisicion y es un proceso que nos indicaran sobre el tipo de datos que se deben almacenar y cuanto de esos datos deben estar disponibles. El custodio de los datos es quien tiene acceso a todos los datos asociados con la solicitud, siendo responsable de evaluar la retencion legal y comprender donde comenzar a adquirir esos datos. Los datos serán almacenados en un area separada llamada Informacion Almacenada Electronicamente (ESI)
- Chain of custody; la cadena de custodia es una forma de asegurar que los datos adquiridos no han sido alterados y permanecen en su estado original y esto lo realizamos utilizando hashes y firmas digitales para mantener la integridad de los datos y comprender quien accede a ellos
- Acquisition; la adquisicion de los datos suele ser el primer paso y es posible que necesitemos obtenerlos de muchos tipos de fuentes diferentes como discos duros, RAM, firmware, archivos de SO, etc. En caso de ser una maquina virtual es recomendable obtener una imagen del sistema que contiene todos los archivos y toda la informacion sobre esa maquina virtual
- Reporting; es necesario crear informes detallados sobre el proceso de adquisición de datos para comprender como se adquirieron y tambien para el proceso legal. Tambien describir todos los pasos que se realizaron para obtener los datos desde su fuente original para que un tercero pueda revisar y comprender todas las verificaciones de integridad que se implementaron para que puedan sentirse seguros que los datos que estan viendo son una representación adecuada de los datos originales. Es comun pedir un analisis de los datos obtenidos para luego dejar que los encargados del caso puedan sacar conclusiones sobre lo que sucedió con los datos.
- Preservation; la preservacion de los datos obtenidos es muy importante por lo que es importante realizar copias exactas para luego utilizar las copias para el analisis y al trabajar con las copias impide que se realicen cambios en la fuente de datos original
- E-discovery; el descubrimiento electronico es el proceso de recopilar, preparar, revisar, interpretar y producir documentos electronicos. Este proceso se trata de adquirir datos para luego proporcionarlos al profesional forense
4.9 Dado un escenario, utiliza fuentes de datos para apoyar una investigación
Log data
- Firewall logs; el firewall regularmente monitorea el trafico desde el interior hacia el exterior y viceversa donde podemos obtener datos sobre las direcciones IP de origen y destino, numeros de puertos y ver que hace el firewall con esos flujos de trafico. En los NGFW podemos ver información de las aplicaciones que están en uso, información de las URLs
- Application logs; las aplicaciones que utilizamos también pueden crear archivos de registro que pueden ser muy útiles a la hora de analizar eventos de seguridad como el registro del visor de eventos de Windows en la sección de registro de aplicaciones y en linux se pueden ver en el directorio /var/log. Toda esta informacion podria agruparse en un SIEM
- Endpoint logs; una computadora, laptops, celulares servidores, agrupan una gran cantidad de logs como por ejemplo eventos de inicio o cierre de sesion, informacion sobre eventos del sistema o procesos que se ejecutan en ese punto final y tambien se pueden agrupar en un SIEM
- OS-specifc security logs; hay una gran cantidad de logs de seguridad almacenada en los propios sistemas operativos para poder monitorear aplicaciones individuales, poder ver si hay ataques de fuerza bruta o algun cambio en archivos criticos del sistema y cualquier cosa relacionada con la autenticación
- IPS/IDS logs; un registro IPS proporcionará informacion sobre vulnerabilidades conocidas o tipos de ataques conocidos
- Network logs; tambien hay una gran cantidad de logs de registros que podemos recopilar d enuestros dispositivos de infraestructura de red como router, switches, AP, concentradores VPN, etc.
- Metadata; a veces es posible recopilar informacion importante contenida en los documentos que se transfieren a traves de la red, por ejemplo, los metadatos de un correo electronico, o metadatos de fotografias tomadas por un celular.
Data sources
- Vulnerability scans; puede detectar si hay dispositivos que no tienen un firewall configurado, que no tenga antivirus o dispositivos que esten mal configurados
- Automated reports; la mayoria de los SIEM tienen la capacidad de crear un conjunto de informes automatizados.
- Dashboards; es util tener un resumen de la informacion que se pueda ver y generalmente estan en un panel de control de los SIEM u otros dispositivos y pueden ser personalizables
- Packet captures; uno de los mejores lugares para recopilar informacion es en la red por lo que se pueden analizar los paquetes que circulan por la red con herramientas como Wireshark brindando una gran cantidad de informacion sobre el funcionamiento de los equipos de red, las aplicaciones y cualquier problema de seguridad
Dominio 5.0 Gestión y Supervisión de Programas de Seguridad
5.1 Resume los elementos de una gobernanza de seguridad efectiva
Guidelines
uno de los objetivos principales de todo administrador de seguridad es crear Confidencialidad, Integridad y Disponibilidad (CIA) y para proporcionar esta CIA necesitamos reglas o politicas que todos sigan para poder mantener este tipo de seguridad. Estas politicas brindar lo que debemos hacer y porqué debemos hacerlo.
Policies
la mayoria de las empresas tiene Politicas de seguridad de la información detalladas y es como una lista maestra de todas las políticas que se deben seguir para mantener el tiempo de actividad, la disponibilidad y la seguridad de la red. En otras organizaciones estas políticas de seguridad son mas que una simple recomendación ya que pueden ser un mandato que la organización debe tener y seguir y pueden ayudar a responder preguntas sobre la seguridad de su infraestructura. La politica tiene una lista de los roles y responsabilidades de todos los asociados con la seguridad en la organización y de esta manera sabemos con quien debemos comunicarnos cuando tengamos preguntas sobre alguna de nuestras preocupaciones de seguridad
- Acceptable Use Policy (AUP); las politicas que se aplican a todos en la organizacion son las Politicas de Uso Aceptable (AUP). Esto define lo que los usuarios pueden hacer con la tecnologia que se les ha proporcionado, por ejemplo define lo que es aceptable para todos cuando usan sus celulares o computadores. Tambien puede usarse para proteger a la organizacion en caso de cualquier responsabilidad legal, por ejemplo el despido de alguien que no siguió las normas de AUP
- Business continuity; una politica de continuidad empresarial se podria utilizar cuando la tecnologia no está disponible por lo que tenemos que acudir a la politica de continuidad empresarial para seguir cuales son los pasos que podriamos realizar para reemplazar la tecnologia no disponible como transacciones manuales de ventas o llamadas telefonicas para confirmar productos que se necesiten. Es importante planificar antes de que surja el problema especifico, por lo que requiere una gran documenentacion y pruebas para garantizar que los planes de continuidad comercial puedan funcionar correctamente
- Disaster Recovery Plan (DRP); el plan de recuperacion ante desastre se puede pensar como un plan de continuidad empresarial que se aplica a todos en la organizacion afectados por un desastre. Los desastres podrian ser naturales, falla tecnologica o del sistema o un desastre creado por un humano
- Security incidents; tambien se debe tener documentacion detallada sobre como lidiar con diferentes incidentes de seguridad, por ejemplo la instalacion de un malware, por lo que deberia existir un conjunto de politicas de seguridad que determinemos los proximos pasos para manejar este tipo de problemas
- Incident response roles; para poder reaccionar ante tipos de incidentes de seg, necesitamos un equipo especializado que sepa como manejar cada una de las situaciones. A este grupo lo llamamos Roles de Respuesta a Incidentes, por ejemplo el equipo de respuesta a incidentes, el equipo de gestion de seg informatica, oficiales de cumplimiento, personal tecnico, entre otros
- Software development lifecycle (SDLC); en un desarrollo de aplicacion hay un conjunto de procesos y procedimientos asociados con la creacion de software a lo que llamamos el Ciclo de Vida del Desarrollo de Software. Dos de los SDLC mas comunes son el AGILE y el WATERFALL (cascada). El cascada es un ciclo lineal que comienza con los requisitos, luego el proceso de desarrollos, las pruebas, la implementacion y finalmente el mantenimiento continuo. El Agile está diseñado para ser una forma mucho mas rapida de crear aplicaciones, y estas generalmente se realizan mediante diseño, desarrollo, pruebas, implementacion y revision durante todo el proceso varias veces para luego crear la aplicacion.
- change management; otro conjunto de politicas importantes es el de gestion de cambios. Si se necesita realizar algun tipo de cambio, debe haber un proceso asociado a ello para poder evaluar que ese cambio no tendrá un efecto negativo en la organizacion. Normalmente las reuniones se hacen semanales sobre qué cambios se están planificando para la siguiente semana. El proceso de gestion de cambios proporciona documentacion clara sobre la frecuencia que se producirá el cambio, la duracion del cambio, el proceso involucrado para instalar el cambio, y quizas lo mas importante, un procedimiento alternativo si el cambio no sale como se esperaba
Security Standards
Algunas organizaciones prefieren utilizar estandares que ya han sido escritos. Dos organizaciones que proporcionan un conjunto de estandares de seguridad son ISO (International Organization for Standardization) y el NIST (National Institute of Standards and Technology).
- password; un conjunto de estandares de seguridad que todos debemos conocer y seguir son aquellos asociados con las contraseñas, especificamente lo que hace que una contraseña sea buena
- Access control; Una vez que alguien se autentica en un sistema con su contraseña necesitamos otro conjunto de estandares que defina como alguien puede acceder a los datos del sistema o al control de acceso. El control de acceso determina a que tipo de informacion puede acceder alguien y en qué momento puede acceder a esa informacion
- Physical security; una organizacion pueden tener estandares para cada usuario que requieran presentar una credencial de identificacion al llegar
- Encryption; dada las complejidades asociadas con las tecnologias de cifrado, probablemente sea una buena idea tener algunos estandares muy bien documentados sobre como se deben utilizar el cifrado en la organizacion e incluir estandares para la implementacion de esas tecnologias de cifrado, como por ejemplo la forma en que se almacenan las contraseñas mediante un hash o un salt hash y determinar el algoritmo del hash implementado. Tambien los requisitos de cifrado para las diferentes formas de datos (en uso, en transito y en reposo)
Procedures
- Change management; la gestion de cambios asegura que tengamos un conjunto de procesos y procedimientos cada vez que se realiza un cambio en cualquiera de nuestros sistemas. Al implementar estos controles y equilibrios podemos ayudar a prevenir tiempos de inactividad, confusion y errores que surgen cuando se realizar cambios en la organizacion. El proceso se empieza determinando cual podria ser el alcance de este cambio, luego saber que tan riesgoso será hacer el cambio, crear un plan formal para el cambio y luego obtener la aprobacion del usuario final. La mayoria de las empresas tiene una junta de control de cambios donde es responsable de analizar todos los cambios propuestos y luego aprobarlos y programarlos y tambien verificará que haya un plan de respaldo y una vez completado el cambio se debe documentar para que todos sepan que se modificó en el sistema
- Onboarding; el equipo de seguridad tambien se preocupa de incorporar a un nuevo trabajador o una transferencia de un departamento a otro y el equipo le proporcionará al empleado el manual de empleado o una lista de las politicas de uso aceptable que el nuevo empleado debe firmar y aprobar. Tambien se deben crear nuevas cuentas de usuarios y asegurar los permisos del usuario junto con proporcionarle todo el hardware necesario para que pueda trabajar.
- Offboarding; tambien debemos crear politicas y procedimientos formales para la salida de un trabajador
- Playbooks; los manuales definen un conjunto de pasos que deben seguirse en el caso de un evento particular, por ejemplo si necesita investigar una violacion de datos, debe haber un playbook que describa exactamente qué se debe hacer primero, que se debe hacer segundo y así sucesivamente. Tambien debe hacer un manual para un ransomware. Una vez creados estos manuales se podrian integrar a una plataforma SOAR (Seguridad, Orquestacion, Automatizacion y Respuesta) para integrar muchos productos en una unica plataforma y poder automatizar las tareas mundanas y permitir que los equipos de seguridad se concentren en realizar otro tipo de trabajos
Monitoring and revision
siempre hay nuevas tecnologias y nuevos proceso que necesitamos integrar en los sistemas, es por eso que necesitamos monitorear constantemente y en algunos casos revisar los procesos y procedimientos que utilizamos diariamente
Types of governance structures
- Boards; la junta directiva es un panel de especialistas que establece las tareas o la serie de requisitos que debe seguir un comité y generalmente el comité determina la mejor forma de implementarlos.
- Committees; los comites suelen estar formados por expertos en la materia y pueden incluir a un miembro de la junta como parte del comité. El comité recibirá instrucciones de la junta sobre qué tareas deben llevarse a cabo y luego trabajara para cumplir con esos objetivos
- Government entities; la presentacion y el alcance son muy diferentes en las entidades gubernamentales a las de una organizacion privada dado a que la primera trabaja para las personas por lo que las reuniones tienden a ser abiertas al publico.
- Centralized/Decentralized; tanto para las organizaciones publicas y privadas hay diferentes maneras de abordar la gobernanza, ya sea centralizada o descentralizada. En la centralizada tienen a haber un grupo que maneja las decisiones de toda la organizacion. La descentralizada esas decisiones pueden ser tomadas por personas que realizan el trabajo en especifico
External considerations
- Regulatory; los profesionales de la seguridad informatica deben conocer las regulaciones asociadas con la organizacion que trabajan y el tipo de datos que recopilan ya sea de alguna aplicacion y archivos de registros de esa aplicacion. Tambien puede existir el requisito de conservar ciertos tipos de informacion durante un periodo prolongado de tiempo. Por ejemplo HIPAA que es la Ley de Portabilidad y Responsabilidad del Seguro Medico y garantiza que nuestra informacion de atencion medica esté protegida.
- Legal; hay requisitos legales asociados como parte del trabajo si trabaja en seguridad informatica, lo que significa que debe haber un conjunto de procesos y procedimientos formales para que el equipo de TI pueda denunciar cualquier actividad legal y tambien es responsable de responder ante una retencion legal. Tambien hay reglas sobre la divulgacion de violaciones de seguridad, lo que significa que si la organizacion descubre una violacion de seguridad tiene la obligacion legal de revelar dicha violacion
- Industry; habrán diferencias de consideraciones de seguridad segun las industrias. Por ejemplo si trabaja con generacion de energia electrica puede haber un conjunto de requisitos muy estrictos sobre como alguien puede acceder a esa informacion.
- Local/Regional; todos los datos tienen que estar asociados al area en donde se recopila la informacion
- Global; es una tarea mas compleja ya que existen diferentes leyes de proteccion y seguridad segun el lugar del mundo al que se dirija.
Roles and responsabilities for systems and data
hay muchas personas diferentes en la organizacion responsables de diferentes aspectos de los datos que almacenamos
- Owners; el propietario de los datos suele ser alguien de un nivel superior en la organizacion que es ampliamente responsable de los datos que se almacenan. Por ejemplo, el viceprecidente de ventas seria el propietario de todos los datos de la relacion con los clientes, y el tesorero de la empresa seria el propietario de toda la informacion financiera. Estas personas son responsables de supervisar todos los aspectos de estos datos y son responsables de todos los datos asociados con esa funcion en particular.
- Data Controllers; el responsable de controles de datos gestiona como se utilizarán los datos y muy a menudo proporciona instrucciones al data Processor sobre como deben utilizarse esos datos
- Data Processors; el responsable de procesamiento de datos es el que efectivamente procesa o utiliza esos datos. Por ejemplo un controlador de datos podria ser alguien como su departamento de nominas y un procesador de datos podria ser alguien como una empresa de nominas que se encarga de realizar los pagos a la empresa del controlador de los datos
- Custodians/stewards; muy a menudo hay un custodio o un administrador de datos asignado a determinados tipos de datos y son responsables de la seguridad de dichos datos y de garantizar que sean precisos y privados junto con ser el responsable de que la organizacion cumpla con todas las leyes o regulaciones asociadas con esos datos, responsables de asignar etiquetas de sensibilidad a los datos para luego asociar esas etiquetas con el control de acceso para que los usuarios puedan acceder a esos datos
5.2 Explica los elementos del proceso de gestión de riesgos
Risk identification
La mayoria de las organizaciones cuentan con algun nivel de gestion de riesgos que les permite identificar donde podrian estar los riesgos y abordarlos antes de que se conviertan en un problema mucho mayor
Risk assessment
hay diferentes formas de realizar una evaluacion de riesgos y cada organizacion tiene requisitos y preocupaciones diferentes con respecto a las amenazas.
- One-time; una organizacion podria realizar una evaluacion de riesgos unica asociada generalmente con algun otro proyecto que pueda estar en curso y la evaluacion de riesgos está diseñada para abordar cualquier inquietud de ese proyecto
- Continuous; en algunas organizaciones esta evaluacion de riesgo es un proceso continuo, vemos esto a menudo con el proceso de control de cambios con el fin de comprender cual puede ser el riesgo de implementar ese cambio
- Ad hoc; es una frase que significa “Para esto” que significa que la utilizamos unicamente para este proposito. Cuando realizamos una evaluacion Ad hoc la realizamos para un proposito especifico. Por ejemplo, descubren que hay un nuevo ataque que están atacando a otras empresas del rubro de la nuestra y se quiere determinar si nuestra organizacion susceptible a este riesgo en especifico y para esto se creara una evaluacion ad hoc que analizará solo este tipo de ataque especifico y verá como puede aplicarse a su organizacion
- Recurring; algunas organizaciones realizarán evalucaiones de riesgos segun un cronograma estandar. Pueden ser una evaluacion interna sin necesidad de acudir a un tercero externo. Tambien pueden haber evaluaciones de riesgos requeridas como parte de un mandato, por ejemplo si la organizacion mantiene numeros de tarjetas de creditos archivados, es posible que se le solicite realizar una evaluacion de riesgos anual segun el Estandar de Seguridad de Datos de la Industrial de Tarjetas de Pago o PCI DSS
Risk analysis
- Qualitative; la determinacion de los niveles de riesgo puede variar ampliamente segun la cantidad de variables diferentes involucradas. Una forma de evaluar el riesgo puede ser crear una evaluacion de riesgo cualitativa. Con este tipo de evaluacion examinará los factores de riesgo individuales y los diferentes criterios para cada uno de esos factores
- Quantitative; puede haber ciertos riesgos para los cuales podemos calcular un valor especifico, a lo que llamamos evaluacion de riesgo cuantitativa y podria comenzar con un ARO (Tasa Anualizada de Ocurrencia) lo que nos permite determinar con qué frecuencia ocurrira este riesgo en un año. Tambien podríamos querer asignar un Valor del Activo que está en ese riesgo lo que se abrevia como AV. Otro valor importante es el factor de exposicion (EF) y es el porcentaje del valor que se perdió debido a ese riesgo en particular, por ejemplo, si perdemos una cuarta parte del activo el factor de exposicion es 0,25 y si perdemos todo el activo el factor de exposicion es 1,0
- Single Loss Expectancy (SLE); con los datos anteriormente dados podemos calcular una evaluacion de riesgo cuantitativa y comenzaremos con SLE que es la Expectativa de Perdida Unica que recibimos si ocurre un solo evento y se puede calcular tomando el valor del activo (AV) y multiplicarlo con el Factor de Exposicion (EF). Por ejemplo, notebook robado con un valor aproximado del activo (AV) de $1.000 x 1,0 (EF) = $1.000 de Expectativa de Perdida Unica (SLE).
- Annualized Loss Expectancy (ALE); la Expectativa de Perdida Anualizada (ALE) es para calcular que en un solo año producirán varios robos de notebooks y para calcular la ALE multiplicamos la Tasa de Ocurrencia Anualizada (ARO) por Expectativa de Perdida Unica (SLE). Por ejemplo, si esperamos siete notebooks robados en un año su Tasa Anualizada de Ocurrencia (ARO) es de 7 y lo multiplicamos por la Expectativa de Perdida Unica (SLE) $1.000 lo que tendriamos una Expectativa de Perdida Anualizada (ALE) de $7.000.
- Impact; en nuestros calculos de riesgos tenemos en cuenta diversos impactos de eventos que pueden ocurrir y el mas importante de ellos seria la vida, por lo que queremos asegurarnos que todos en la organizacion estén seguros. Luego tenemos que considerar el impacto sobre la propiedad, el impacto en la seguridad si ocurre un evento riesgoso, tambien hay un impacto financiero
- Likelihood and probability; la posibilidad de un riesgo es un valor cualitativo, por lo tanto podriamos considerar que un riesgo es raro, posible, casi seguro o algun otro tipo de medición cualitativa. La probabilidad de riesgo tiene a ser un numero cuantitativo, de esta forma podemos asociar una estadistica o una medicion a ese riesgo especifico.
Risk appetite and tolerance
No todos los riesgos requiere que una organizacion actue. Puede existir un cierto grado de riesgo que la organizacion esté dispuesta a asumir, a ese valor lo llamamos apetito por el riesgo y algunas empresas estableceran un valor cualitativo para este apetito y lo llamamos postura de apetito por el riesgo, por lo que para un riesgo en particular podrian decir que son conservadores, neutrales o expansivos ante ese tipo de riesgo. Otro valor importante a considerar es la tolerancia al riesgo, con frecuencia se trata de una variacion mayor que el apetito por el riesgo, por lo tanto podriamos tener un apetito de riesgo relativamente bajo y nuestra tolerancia al riesgo podria estar apenas por encima de ese valor de apetito. Un ejemplo es que el limite de seguridad en una carretera es de 100 km/h y ese numero lo pudo el gobierno por lo que el apetito al riesgo es de 100km/h en cambio los policias no nos multaran hasta llegar a 120km/h por lo que la tolerancia al riesgo es de 120km/h poniendose levemente por encima al apetito
Risk register
El objetivo del registro de riesgo es documentar cada uno de esos riesgos individuales de un proyecto y si es posible proporcionar algunas opciones o soluciones para evitar ese riesgo
- Key risk indicators; cada linea del registro de riesgos contendrá un indicador de riesgo clave que detalla cuales podrian ser esos riesgos.
- Risk owners; para cada uno de esos indicadores claves de riesgos debemos asignar un propietario que gestionará o será responsable de ese riesgo en particular
- Risk threshold; luego debemos determinar cual será el umbral de riesgo para ese proyecto asegurandonos de que haya un equilibrio entre cuanto dinero gastaremos en el riesgo y cuanto terminará costando ese riesgo a la empresa
Risk management strategies
Una organizacion puede utilizar distinas estrategias para afrontar el riesgo una de ellas pueden ser
- Transfer; transferir el riesgo significa que trasladamos el riesgo bajo el control a un tercero, por ejemplo la compra de un seguro de ciberseguridad.
- Accept; es cuando la empresa simplemente acepta el riesgo siendo la linea de accion mas comun y permite a la empresa decidir qué desea hacer con ese riesgo. Puede haber el caso que la empresa acepte el riesgo y lo haga con la exencion de sus politicas existente, por ejemplo, se necesita una maquina pero esta maquina no acepta que el windows conectado se instale parches de seguridad o actualizaciones pero la politica de la empresa dice que todos sus equipos necesitan parches y actualizaciones actualizados, por lo que se haría una exención solo para ese equipo conectado a la nueva maquina siempre que la maquina no esté conectado a la red. Tambien puede haber casos en lo que se acepte el riesgo pero haya una excepcion a las politicas de seguridad implementadas, por ejemplo una politica que diga que cada dispositivo debe recibir el parche dentro de los tres dias posteriores a la liberacion del parche, pero durante las pruebas, se descubre que el parche provoca el bloqueo de un software critico y para resolver este conflicto la empresa puede crear una excepcion que permita esperar mas de tres dias para la actualizacion del parche
- Avoid; otra estrategia de gestion de riesgos seria evitar el riesgo por completo, lo que significa que no hay necesidad de proporcionar ninguna gestion de riesgos adicional por que ese riesgo se ha eliminado
- Mitigate; por ejemplo si nos preocupa el riesgo que vienen de internet tal vez queramos invertir en un NGFW que mitigue algunos de los problemas asociados con esa conectividad.
Risk reporting
una organizacion puede tener cientos de riesgos que necesiten seguimiento y una forma de realizarlo es mediante el uso de informes de riesgos. Estos informes crean una lista de todos los riesgos que la empresa está rastreando y permite una descripcion de cada uno de esos riesgos y como manejarlos
Business impact analysis
- Recovery Time Objective (RTO); el Objetivo de Tiempo de Recuperacion es cuanto tiempo pasará hasta que podamos volver a estar en funcionamiento. el RTO es un marco de tiempo que define cuanto tiempo debe transcurrir antes de que podamos ponernos en funcionamiento
- Recovery Point Objective (RPO); el Objetivo de Punto de Recuperacion (RPO) es un punto en el tiempo en el que podemos decir que ya estamos en funcionamiento, por ejemplo, se consideraria operativos cuando contemos con 30 dias de informacion en los servidores y en caso de no tener esa informacion tendriamos que buscar en el servidor de backup para luego considerarse operativo, por lo que a esos 30 dias de informacion consideramos como RPO
- Mean Time To Repair (MTTR); la cantidad promedio de tiempo que lleva solucionar un problema que incluye tanto el tiempo para diagnosticar, como el de conseguir un reemplazo, el tiempo para instalar el reemplazo y luego configurar el reemplazo
- Mean Time Between Failures (MTBF); el Tiempo Promedio Entre Fallas es el tiempo estimado que el sistema funcionará antes de que haya otra interrupcion y se usa con fines de planificacion para saber que tan riesgoso podria ser usar ese equipo cuando lo estemos por comprar
5.3 Explica los procesos asociados con la evaluación y gestión del riesgo de terceros
Vendor assessment
como siempre se trabaja con proveedores es posible que en alguna parte de los datos de la empresa se comparte con ese tercero por ejemplo, contratar a una empresa para que realice pagos de nominas de nuestros trabajdores, por esa razon siempre es buena idea realizar un analisis de riesgos del tercero con el fin de saber que está pasando con nuestros datos y como está protegiendo la información que le estamos brindando. Es recomendable incluir la informacion de evaluacion de riesgos en el contrato que se tiene con ese tercero para garantizar que todos comprendan las expectativas de esta evaluacion de riesgos y establecer sanciones si se incumple alguna parte de ese acuerdo
- Penetration testing; Un tipo común de evaluación de riesgos son las pruebas de penetración. Es similar a realizar un análisis de vulnerabilidad excepto que intentamos explotar activamente las vulnerabilidades encontradas. Estas pruebas incluyen un documento llamado (Rules of Engagement (Reglas de Compromiso) y establece los parameros para que todos comprendan el alcance de la prueba y exactamente qué dispositivos se probarán
- Right-toaudit clauses; el derecho a auditoria se establece en el contrato como cláusula que se tiene con una empresa proveedora o prestadora de servicio donde le entregaremos nuestros datos y el fin de establecer esta clausula en el contrato es que todos entiendan que se realizarán auditorias periódicas.
- Evidence of internal audits; en muchos casos ni nosotros ni el proveedor son lo que realizan las auditorias, ya que un tercero la realizaría como alguien que está fuera del alcance del contrato y a veces estas auditorias son necesarias según el tipo de datos almacenados o puede ser parte del cumplimiento de la empresa asegurarse que se realice una auditoria. Estas auditorias se centran en todos los controles de seguridad que rodean la relación entre nosotros y el proveedor
- Supply chain analysis; la cadena de suministro describe todo el proceso que ocurre desde el principio con las materias primas hasta que se crea el producto final, por lo que existen preocupaciones de seguridad que ocurren en cada paso del proceso de la cadena de suministro. Por esta razón a menudo es buena idea realizar un análisis de la cadena de suministro. Esto dará la oportunidad de comprender todo el proceso y donde pueden surgir problemas de seguridad
- Independent assessments; podria ser valioso traer a alguien de afuera que tenga una perspectiva diferente y así estas evaluaciones independientes pueden brindarnos la perspectiva que no se puede obtener dentro de la organización
Vendor selection process
- due diligence; la debida diligencia es el proceso de investigar y obtener mas información sobre una empresa antes de decidir incorporar a esa organización a nuestra empresa como proveedor aliado comercial. Lo que podria incluir verificaciones de antecedentes o entrevistas con personas de esa organización
- Confict of interest: es importante que al trabajar con un tercero se mantenga una relación comercial pero es importante aclarar que no haya un conflicto de interés entre ambas partes para no comprometer el juicio de cualquiera de las partes de la relación comercial.
Vendor monitoring
Una vez firmado el contrato con un tercero querrá tener un monitoreo continuo de la relación entre las dos compañías, especialmente desde la perspectiva de seguridad de TI. Es común que esos procesos de monitoreo ocurran con frecuencia para realizar controles de salud financiera, revisiones de seguridad, entre otros
Questionnaires
Una forma común de realizar el seguimiento del proveedor es enviar un cuestionario al tercero. Este cuestionario es una forma sencilla de obtener mas información sobre la forma en que el proveedor hace negocios. Por ejemplo, es posible que necesitemos saber como es el proceso de diligencia debida de los proveedores y que hacen para evitar el conflicto de interés, o saber que planes tiene el proveedor para la recuperación ante desastres
Agreement types
- Service Level Agreement (SLA); si trabajamos con un proveedor de servicios, es posible que desee establecer ciertos requisitos de tiempo de actividad o disponibilidad, por lo que podemos integrar esos requisitos en un documento llamado Acuerdo de Nivel de Servicio o SLA. Esto permite establecer términos mínimos para el servicio que proporcionará el tercero
- Memorandum of Understanding (MOU); si se está iniciando una asociación con un tercero, es posible que desee comenzar con un Memorando de Entendimiento (MOU). Por lo general proporciona objetivos muy amplios de lo que las dos organizaciones lograrán al trabajar juntas. Podria incluir declaraciones de confidencialidad aunque es algo informal ya que no es un contrato firmado
- Memorandum of Agreement (MOA); lo que podria venir a continuación en esta asociación es un Memorando de Acuerdo o MOA. Este es un paso por encima del MOU y describe con mas detalle la relación entre las dos organizaciones. Tambien este documento detalla como dos empresas pueden trabajar juntas y puede haber alguna información legalmente vinculante dentro del documento pero no es un contrato y por esto no proporciona ningún tipo de garantía legal
- Master Service Agreement (MSA); si se tendrá una relación continua con un tercero, se podria crear un Acuerdo Marco de Servicios (MSA). Este acuerdo es un contrato legal que establece los términos entre ambas organizaciones y establece un marco que puede usarse para trabajos adicionales que podrian producirse en el futuro. Por ejemplo, podria incluir los términos del servicio, podria haber una descripción general de la facturación y describir como podria funcionar el sistema de pago
- Work Order (WO) / Statement of Work (SOW); los Servicios adicionales se documentarian en una Orden de Trabajo (WO) o en una Declaracion de Trabajo (SOW). En SOW suele incluir un desglose detallado de los servicios que se proporcionarán y cuando y a menudo se utiliza junto con le MSA para que no tengamos que renegociar los términos básico del contrato y poder centrarnos en este conjunto particular de tareas. Una declaración de trabajo tendría el alcance del trabajo, la ubicación donde se realizará el trabajo, el cronograma, etc
- Non-disclosure agreement (NDA); puede haber ocaciones en que la información compartida entre dos organizaciones deba ser confidencial y una forma de acordar contractualmente esta confidencialidad es mediante el uso de un Acuerdo de No Divulgacion o NDA. Cualquier cosa que se necesite mantener confidencial se incluirá en los detalles del NDA. El NDA puede redactarse de tal manera que solo una de las partes esté obligada a mantener la confidencialidad y a esto lo llamamos Acuerdo de Confidencialidad Unilateral o Unidireccional
- Business Partners Agreement (BPA); un acuerdo de socios comerciales o BPA describen los detalles financieros asociados con el acuerdo y describe que tipo de participación accionaria se adquiere cuando se inicie una asociación formal con un tercero y también podria describir como funcionará la empresa con la asociación, por ejemplo, quien en la sociedad tomará las decisiones comerciales o también indicar en el BPA que para si ocurre un desastre que cierra el negocio
5.4 Resumir los elementos de un cumplimiento de seguridad efectivo
Compliance reporting
- Internal; muchas organizaciones realizarán sus propios controles de cumplimientos internos y a menudo esto está asociado a un Oficial Central de Cumplimiento (CCO) y esta persona es la responsable de asegurarse de que toda la organizacion cumpla con los requisitos estatales, locales, o de otro tipo. Esta oficina tambien se encarga de informar a otros sobre el estado de cumplimiento de la organizacion
- External; tambien es posible tener requisitos de cumplimientos externos, especialmente cuando trabaja con un tercero que ha establecido requisitos para su empresa. Esto tambien puede requerir informes continuos, por lo que es posible que tenga que crear un informe de cumplimiento cada año. Un ejemplo de cumplimiento normatibo seria SOX que se conoce como la Ley de Reforma Contable de Empresas Publicas y Protector del Inversor. Otro cumplimiento regulatorio es HIPAA que significa Ley de Portabilidad y Responsabilidad del Seguro Medico y garantiza que la informacion medica de todos en EEUU permanezca privada
Consequences of non-compliance
- Fines and Sanctions; podrian haber multas y sanciones importantes en caso de no cumplir con las normas establecidas
- Reputational damage; puede haber daños a la reputacion si no cumple con las normas, por ejemplo, muchos estados tienen requisitos de informar si una organizacion es atacada o vulnerada, y el daño a la reputacion de revelar ese ataque podria causar que los precios de las acciones de esa empresa caigan al menos en un corto plazo
- Loss of license; se podria perder la licencia particular asociada con el cumplimiento, lo que podria ocasionar un golpe economico importante para la empresa
- Contractual impacts; parte del cumplimiento se realiza a nivel contractual, donde hay un acuerdo entre dos organizaciones para cumplir y si una empresa no mantiene ese cumplimiento entonces se incumple el contrato
Compliance monitoring
se puede ver como el incumplimiento puede afectar negativamente a una organizacion y es por eso que muchas organizaciones tendrán personas especificamente encargadas de monitorear el cumplimiento
- Due diligence/care; la “debida diligencia” y el “debido cuidado” son palabras asociadas con el monitoreo del cumplimiento. Esta es una forma de describir como las empresas estan actuando de buena fe y honestamente sobre los terminos del cumplimiento. Normalmente, las actividades que usted realiza internamente se denominan debido cuidado, y cualquier actividad que realice con un tercero se basaria en la debida diligencia
- Attestation and acknowledgement; es comun que el ejecutivo que está a cargo de este proceso de cumplimiento sea el que firme indicando que el cumplimiento está efectivamente en regla. A esto lo llamamos Certificacion y Reconocimiento y en ultima instancia es el ejecutivo quien se encarga de garantizar que toda esa información se proporcione de buena fe
- Internal and External; una gran empresa con muchos tipos de productos puede tener una gran cantidad de requisitos de cumplimiento y es por eso que es importante proporcionar un seguimiento continuo del cumplimiento. Normalmente se utilizan herramientas internas en la organizacion para realizar un seguimiento del estado de las tareas de cumplimiento. Tambien puede que tengas que interactuar con terceros para reunir mas informacion y determinar si realmente cumples con la normativa
- Automation; muchas organizaciones encontrarán formas de automatizar este proceso tanto como sea posible. Los requisitos de cumplimiento son bastantes diferentes entre los distintos tipos de empresas, por lo que la automatizacion variará mucho de una empresa a otra. Afortunadamente existe un mercado de sistemas automatizados de monitoreo de cumplimiento que recopilan datos de personas, de terceros y de otras partes de la organizacion para recopilar la mayor cantidad de informacion de cumplimiento posible y asegurarse de estar actualizado con los detalles de cumplimiento
Privacy
- Legal implications; en muchos lugares, la privacidad comienza a nivel local y estatal.
- Local/Regional; Nuestros gobiernos locales recopilan una gran cantidad de datos sobre nuestros hogares, vehiculos e informacion sobre licencias medicas
- National; a nivel nacional, tenemos leyes que protegen la privacidad de todos en el pais, por ejemplo las leyes HIPAA sobre atencion medica son un buen ejemplo de regulaciones que afectan a todos en un pais
- Global; muchos paises estan trabajando juntos para garantizar la privacidad de todos sus ciudadanos independiente de donde vivan. Por ejemplo la ley de privacidad que afecta a varios paises es el GDPR que es el Reglamento General de Proteccion de Datos y se trata de una normativa de la Union Europeaque afecta a la privacidad de todas las personas que viven en la UE y algunos datos que estan protegidos son el nombre, la direccion, la fotografia, los correos, informacion bancaria, publicaciones en redes sociales y mas.
- Data subject; el GDPR define al sujeto interesado como cualquier informacion relativa a una persona fisica identificada o identificable. En realidad esto incluiria a cualquiera que viva en esos paises de la UE, por lo que el GDPR y otras leyes de privacidad definen la pespectiva de la privacidad de los datos desde la perspectiva del interesado
- Ownership; el concepto de propietario de datos se trata de una persona que tendria la responsabilidad general de los datos, por ejemplo, el vicepresidente de ventas es el propietario de los datos de cualquier relacion con el cliente, el tesorero de la empresa será el propietario de los datos de toda la informacion financiera asociada con la organizacion
- Data Controller vs Data Processor; muchas organizaciones tienen controladores de datos y procesadores de datos. El responsable del controlador o tratamiento de datos tiene que gestionar el modo en que se utilizan estos datos y el procesador de datos es la persona que realmente utiliza los datos, el procesador de datos puede ser interno o un tercero para procesar esos datos. Por ejemplo tenemos un departamento de nominas para pagar y una empresa que realiza los pagos, el departamento de nominas de la organizacion seria el responsable del tratamiento de los datos (data controller) ya que ellos definen cuanto y cuando se les paga a sus trabajadores y esa informacion la entregaria a la empresa que realiza los pagos por lo que tiene que procesar los cheques a todos cada semana. Debido a que hay gran informacion privada, podria ser buena idea utilizar un acuerdo de confidencialidad para que esa informacion permanezca privada
- Data inventory and retention; una empresa que almacena datos tiene un inventario de datos que es una lista de todos los datos que esta empresa recopila y almacena en su organizacion. Esto incluye el propietario de los datos, la frecuencia con la que se actualiza la informacion y el formato de esos datos. Al compartir los datos con un tercero debemos asegurarnos de cumplir con todas las pautas legales de privacidad, por lo que tenemos que entender cual es nuestro inventario de datos, que tipo de datos son y asegurarnos de que si los compartimos todo esté dentro de las leyes y regulaciones existentes
5.5 Explica los tipos y propósitos de las auditorias y evaluaciones
Attestation
La atestación es una opinión de verdad que se asocia a los resultados de una auditoria. Normalmente realizamos una auditoria y luego daremos fe de los resultados de esa auditoria
Internal audits
No es necesario contratar a un tercero para realizar una auditoria, ya que se pueden realizar internamente dentro de la propia organización.
- Compliance; la auditoria interna puede responder preguntas que tenga sobre el cumplimiento y asegurarse de que todas las tareas de cumplimiento se sigan correctamente
- Audit committe; la organización también podria tener un comité de auditoria. Generalmente, este es un grupo que es responsable de toda la gestión de riesgos asociada con una organización. Tambien este comité es el que inicia y detiene cualquier auditoria interna
- Self-assessments; las auditorias a menudo comienzan con una autoevaluación. Esto permite a una organización analizar sus procesos y procedimientos internos y ver que tan bien se ajustan a los requisitos de la organización. El comité de auditoria puede recopilar todas estas autoevaluaciones para tener una idea de donde podria encontrarse la organización en lo que respecta al cumplimiento
External audits
- Regulatory requirements; algunas regulaciones de cumplimiento requieren que un tercero realice la auditoria. En este caso traeremos un grupo externo para poder realizar todas las funciones de esa supervisión en particular
- Examinations; generalmente, esto implica encontrar escritorios para que un auditor externo ingrese a la organización y comience a revisar sus registros. Luego podria recopilar información y reunir detalles adicionales sobre la auditoria
- Assessment; los resultados de esta auditoria generalmente muestran donde se encuentra la empresa hoy en dia con respecto al cumplimiento y donde puede haber un espacio para mejorar en el futuro
Penetration testing
- Physical; las pruebas de penetración físicas pueden ser una herramienta de seguridad importante ya que es fácil eludir la seguridad de un sistema operativo si se tiene acceso físico al dispositivo modificando el proceso de arranque desde otros medios o modificar y sustituir los archivos asociados al sistema operativo. Es por esto que los servidores estan encerrados en un centro de datos de alta seguridad ya que la seguridad física es muy importante
- Offensive; el grupo de pruebas de penetración ofensivos también son llamados equipo rojo y atacan el sistema buscando vulnerabilidades e intentan explotarlas
- Defensive; el grupo de pruebas de penetración defensivo o llamados equipo azul es capaz de identificar los ataques que vienen en tiempo real y bloquear cualquiera de estos ataques antes de que ocurra
- Integrated; la mejor combinación seria integrar estos dos equipos para tener un sistema que constantemente brinde retroalimentación sobre si mismo con el fin de que el cuando el equipo rojo encuentre una brecha le informe al equipo azul para poder parchearla e identificarla mejor la próxima vez
- Known environment; una organización puede proporcionar al evaluador de penetración un entorno conocido de su empresa y esto se conoce como caja blanca
- Partially known environment; una organizacion puede proporcionar al evaluador de penetración un entorno parcialmente conocido de su empresa y esto se conoce como caja gris
- Unknown environment; cuando una organización no proporciona absolutamente nada de información al evaluador de penetración se llama caja negra
- Reconnaissance; el evaluador de pentester utiliza el proceso de reconocimiento para recopilar la mayor información posible sobre el entorno para comprender qué herramientas de seguridad podrian estar implementadas, qué servidores y aplicaciones podrian estar en la organización. Una vez terminado el reconocimiento pueden elaborar un mapa de red completo con todas las direcciones IPs
- Passive reconnaissance; es posible utilizar otras fuentes antes para recopilar información de una conexión de red del cliente y esto se llama reconocimiento pasivo. Este tipo de reconocimiento se hace recopilando información de fuentes que no nos vinculan directamente con la red del cliente, por ejemplo, buscar información en las redes sociales, sitio web corporativo donde se pueda explorar y obtener información de la empresa, foros en línea, ingeniería social, buscar en la basura algún tipo de documento que contenga información importante o hablar con empresas contratista de la organización para averiguar algún tipo de información.
- Active reconnaissance; el reconocimiento activo es una forma mucho mas directa de recopilar información por que uno ingresa a la red y consulta los dispositivos que podrian estar allí. En este tipo de reconocimiento es posible que nos vean ya que enviamos paquetes a través de la red. Un ejemplo de reconocimiento activo es un escaneo de ping o de puertos, consulta de DNS, escaneo de SO o servicios de escaneo de versiones
5.6 Dado un escenario, implemente practicas de concienciación sobre seguridad
Phishing
- Phishing campaigns; en una campaña de phishing se envían correos electrónicos a los trabajadores para ver quien podria hacer clic en los correos falsos enviados por nosotros para luego realizarle una capacitación adicional a esa persona par que no caiga en futuros ataques reales
- Recognize a phishing attempt; queremos que nuestros usuarios reconozcan un intento de phishing buscando errores ortográficos o gramaticales, que miren el nombre de dominio asociado con ese enlace y verifiquen si hay inconsistencias y ver si el correo solicita información personal o credenciales de inicio de sesión
- Respond to reported suspicious messages; si recibes estos intentos de phishing desde el exterior esta es una buena oportunidad para si el proceso de filtrado de correos funciona como se espera, ya que lo ideal es que ese filtro bloquee cualquiera de estos intentos de phishing antes de que llegaran a la bandeja de entrada del usuario. Tambien debe existir un proceso bien conocido por todos para informar cualquier correo sospechoso de phishing al equipo de seguridad de TI
anomalous behavior recognition
- Risky behavior; la conducta de riesgo es también algo que buscamos en la estación de trabajo de un usuario y podria incluir una persona o un servicio que modifique un archivo de host en el dispositivo, tal vez que esté reemplazando un archivo central del sistema operativo o cargando archivos confidenciales desde ese dispositivo
- Unexpected behavior; también buscamos comportamientos inesperados, por ejemplo, que alguien inicie sesión desde otro país y aumento en la cantidad de transferencias de datos desde un dispositivo inesperado
- Unintentional behavior; el comportamiento involuntario también lo buscaríamos, por ejemplo, que alguien escriba un nombre de dominio incorrecto seria un error involuntario, la perdida de un pendrive o configuraciones de seguridad de un equipo mal configurados
Reporting and monitoring
Un equipo de seguridad no estará al tanto de estos problemas a menos que esté constantemente monitoreando e informando sobre este tipo de eventos. Este debe ser un proceso automatizado, donde las alertas se envíen automáticamente al equipo de seguridad.
- Initial; la primera vez que alguien hace clic en un enlace de phishing o realiza algún otro tipo de comportamiento riesgoso podemos abordarlo con capacitación de usuarios para concientizar al usuario sobre el problema en particular
- Recurring; si realizamos un seguimiento constante, podríamos ver si estos eventos vuelven a ocurrir y de ser así podrian necesitar una capacitación mas extensa y agregar o cambiar configuraciones de seguridad para ese usuario
Development
El proceso de monitoreo, reporte y capacitación de los usuarios lo realizan generalmente el equipo de concientización sobre seguridad. Este equipo se enfoca principalmente en este tipo de problemas de los usuarios y pueden crear correos, carteles o algún tipo de capacitación para informar a los usuarios donde podrian estar los problemas de seguridad
Execution
El equipo de concientización sobre seguridad será responsable de crear los materiales de capacitación en seguridad informática y los presentará en línea o en persona y crearán métricas detalladas que muestren al resto de TI cómo pueden estar funcionando los controles de seguridad
User guidance and training
- Policy/handbooks; es importante documentar todas sus políticas de seguridad y tenerlas en un lugar al que todos los usuarios de la empresa puedan consultarlas, podrian estar en línea en la intranet y añadir estas políticas a cada manual del empleado
- Situational awareness; también queremos que los usuarios tengan conciencia de la situación, lo que significa que siempre deben estar atentos a las amenazas, por ejemplo, atentos a los enlaces de correos o archivos adjuntos de un correo de phishing, mensajes de textos extraños o ataques físicos
- Insider threat; las amenazas internas son muy difíciles de identificar por lo tanto necesitamos un enfoque multifactorial para buscar y detener una amenaza interna
- Password management; debemos pensar en la gestión de contraseñas para nuestros usuarios y existen muchas estrategias diferentes para crear una contraseña segura
- Removable media and cables; nuestra capacitación de usuarios también puede incluir medios extraíbles y cables, ya que pueden ser fuentes de problemas de seguridad
- Social engineering; los atacantes son muy buenos en el uso de ing social para intentar obtener información de nuestra comunidad de usuarios. Por lo que debemos asegurarnos que nuestros usuarios estén familiarizados con algunas de las técnicas de ing social mas comunes
- Operational security; los usuarios trabajan con grandes cantidades de datos y queremos que entiendan que tipo de datos pueden ser confidenciales y brindar seguridad adicional para estos datos confidenciales
- Hybrid/remote work environments; otro reto que tenemos son los usuarios que trabajan desde casa ya que añade una serie de preocupaciones de seguridad diferentes, por lo que debemos asegurarnos que nadie permita que sus familiares o amigos accedan a los sistemas que utilizan para trabajar. Agregariamos seguridad adicional a los puntos finales porque están fuera del edificio y es posible que queramos tener mayor seguridad para todo el acceso VPN que usaran